Perceptual Conversational Head Generation with Regularized Driver and Enhanced Renderer
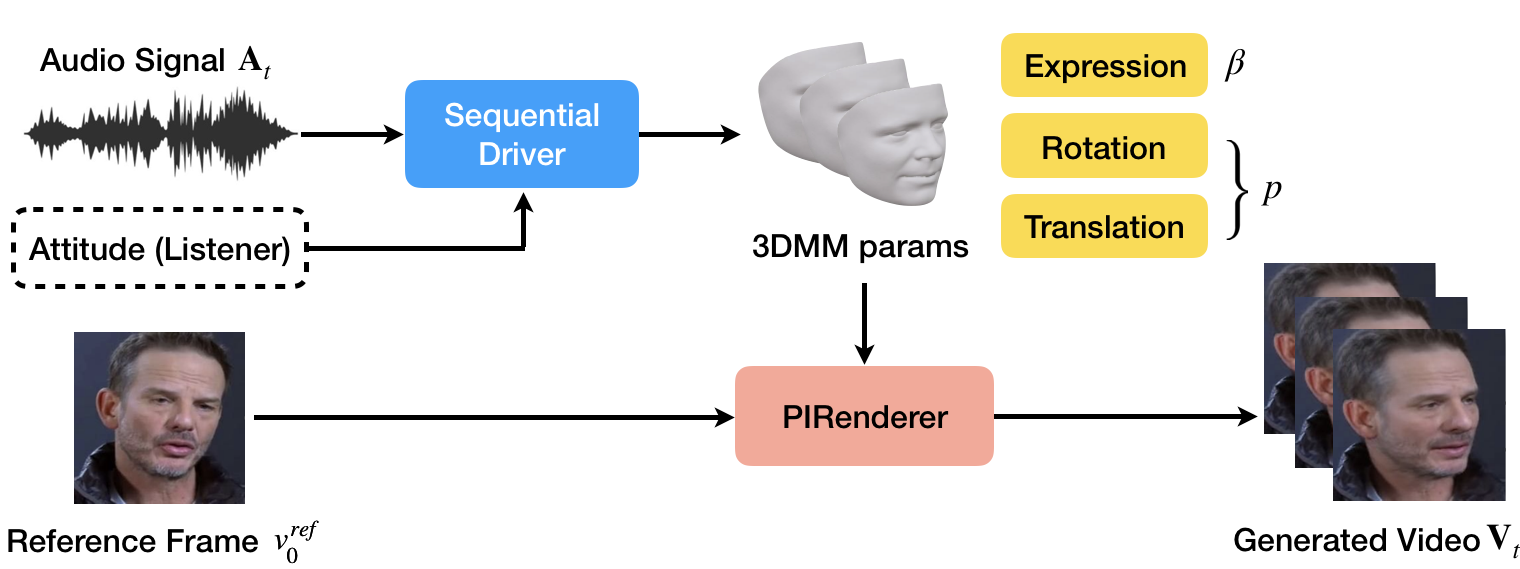
This paper reports our solution for ACM Multimedia ViCo 2022 Conversational Head Generation Challenge, which aims to generate vivid face-to-face conversation videos based on audio and reference images. Our solution focuses on training a generalized audio-to-head driver using regularization and assembling a high-visual quality renderer. We carefully tweak the audio-to-behavior model and post-process the generated video using our foreground-background fusion module. We get first place in the listening head generation track and second place in the talking head generation track on the official leaderboard. Our code is available at https://github.com/megvii-research/MM2022-ViCoPerceptualHeadGeneration.
PDF Abstract

Datasets
Add Datasets
introduced or used in this paper
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
