Pixel Sentence Representation Learning
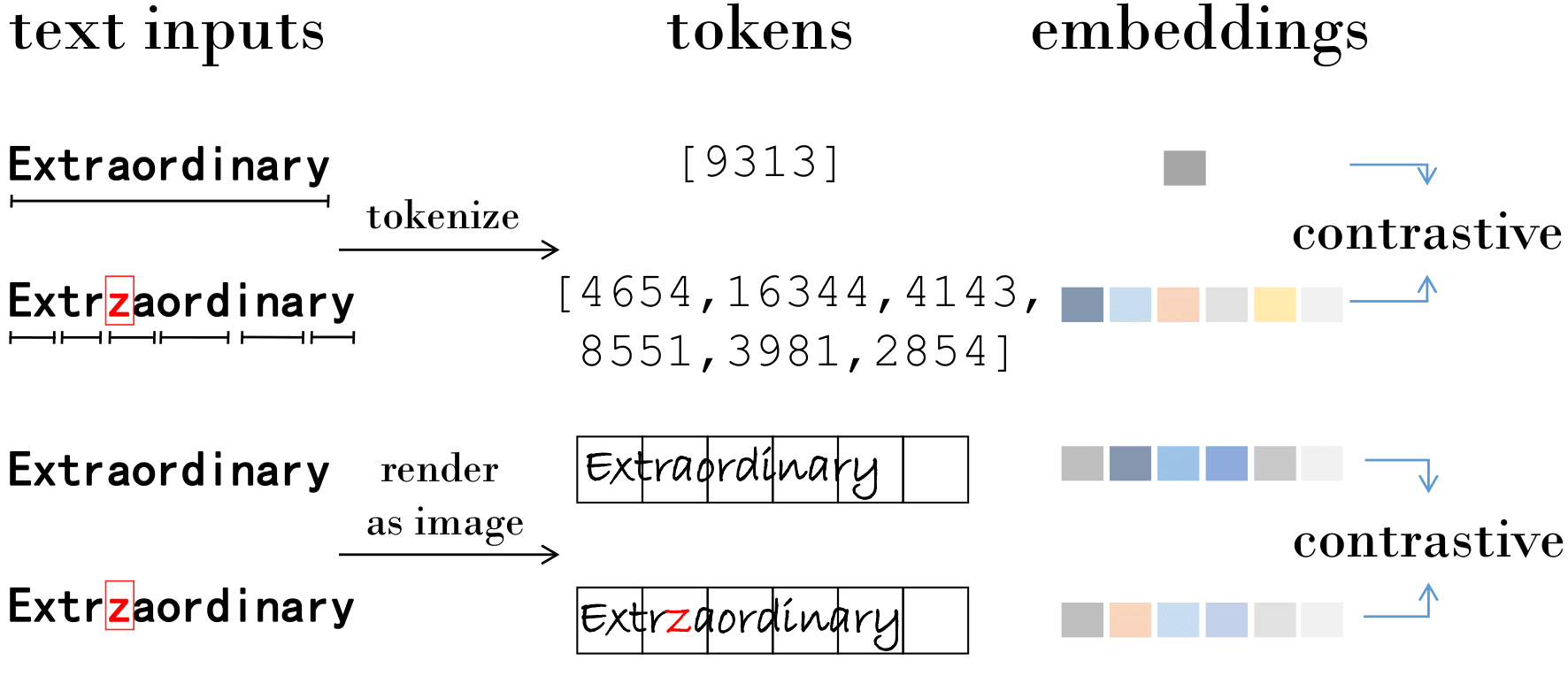
Pretrained language models are long known to be subpar in capturing sentence and document-level semantics. Though heavily investigated, transferring perturbation-based methods from unsupervised visual representation learning to NLP remains an unsolved problem. This is largely due to the discreteness of subword units brought by tokenization of language models, limiting small perturbations of inputs to form semantics-preserved positive pairs. In this work, we conceptualize the learning of sentence-level textual semantics as a visual representation learning process. Drawing from cognitive and linguistic sciences, we introduce an unsupervised visual sentence representation learning framework, employing visually-grounded text perturbation methods like typos and word order shuffling, resonating with human cognitive patterns, and enabling perturbation to texts to be perceived as continuous. Our approach is further bolstered by large-scale unsupervised topical alignment training and natural language inference supervision, achieving comparable performance in semantic textual similarity (STS) to existing state-of-the-art NLP methods. Additionally, we unveil our method's inherent zero-shot cross-lingual transferability and a unique leapfrogging pattern across languages during iterative training. To our knowledge, this is the first representation learning method devoid of traditional language models for understanding sentence and document semantics, marking a stride closer to human-like textual comprehension. Our code is available at https://github.com/gowitheflow-1998/Pixel-Linguist
PDF Abstract




 MultiNLI
MultiNLI
 SNLI
SNLI
 WikiMatrix
WikiMatrix
