POPE: 6-DoF Promptable Pose Estimation of Any Object, in Any Scene, with One Reference
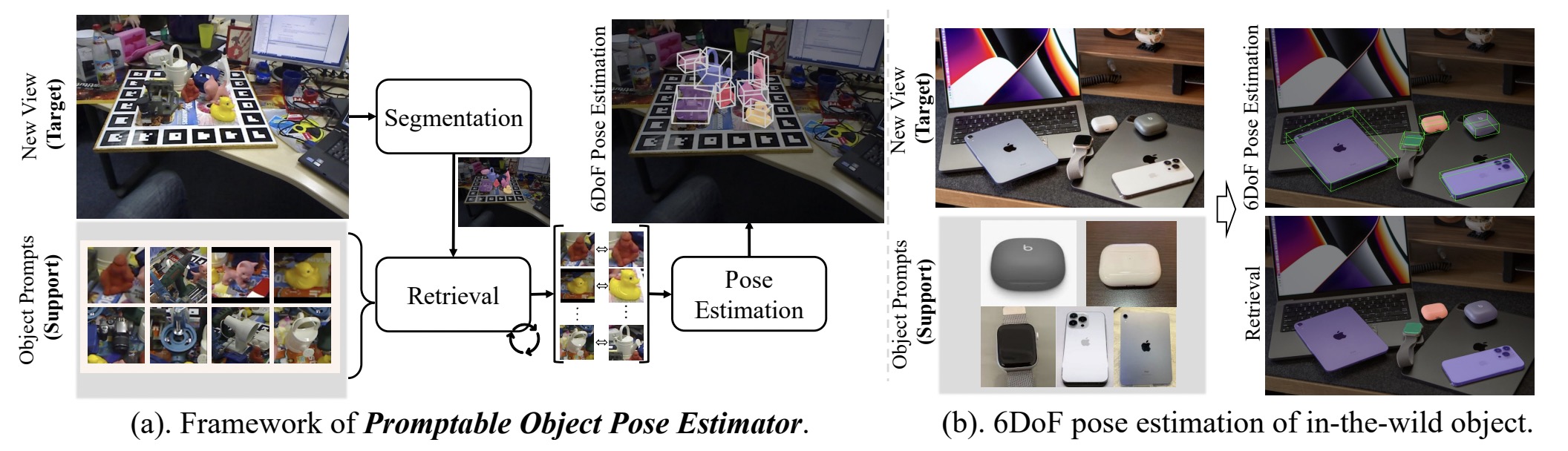
Despite the significant progress in six degrees-of-freedom (6DoF) object pose estimation, existing methods have limited applicability in real-world scenarios involving embodied agents and downstream 3D vision tasks. These limitations mainly come from the necessity of 3D models, closed-category detection, and a large number of densely annotated support views. To mitigate this issue, we propose a general paradigm for object pose estimation, called Promptable Object Pose Estimation (POPE). The proposed approach POPE enables zero-shot 6DoF object pose estimation for any target object in any scene, while only a single reference is adopted as the support view. To achieve this, POPE leverages the power of the pre-trained large-scale 2D foundation model, employs a framework with hierarchical feature representation and 3D geometry principles. Moreover, it estimates the relative camera pose between object prompts and the target object in new views, enabling both two-view and multi-view 6DoF pose estimation tasks. Comprehensive experimental results demonstrate that POPE exhibits unrivaled robust performance in zero-shot settings, by achieving a significant reduction in the averaged Median Pose Error by 52.38% and 50.47% on the LINEMOD and OnePose datasets, respectively. We also conduct more challenging testings in causally captured images (see Figure 1), which further demonstrates the robustness of POPE. Project page can be found with https://paulpanwang.github.io/POPE/.
PDF Abstract


 YCB-Video
YCB-Video
