Privacy Leakage of Adversarial Training Models in Federated Learning Systems
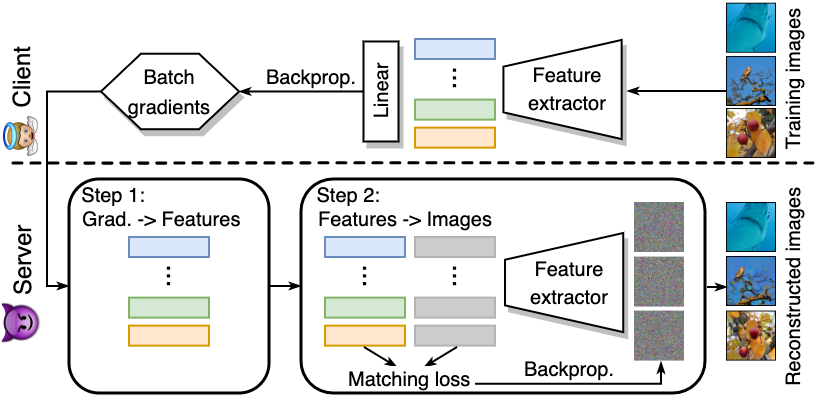
Adversarial Training (AT) is crucial for obtaining deep neural networks that are robust to adversarial attacks, yet recent works found that it could also make models more vulnerable to privacy attacks. In this work, we further reveal this unsettling property of AT by designing a novel privacy attack that is practically applicable to the privacy-sensitive Federated Learning (FL) systems. Using our method, the attacker can exploit AT models in the FL system to accurately reconstruct users' private training images even when the training batch size is large. Code is available at https://github.com/zjysteven/PrivayAttack_AT_FL.
PDF Abstract
Tasks

Datasets
 ImageNet
ImageNet
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
