Provably Fair Representations
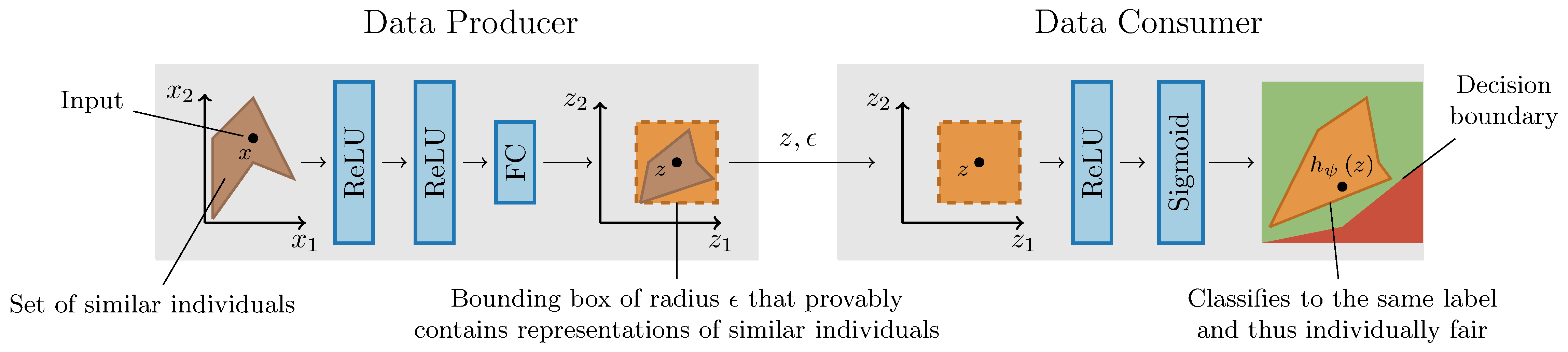
Machine learning systems are increasingly used to make decisions about people's lives, such as whether to give someone a loan or whether to interview someone for a job. This has led to considerable interest in making such machine learning systems fair. One approach is to transform the input data used by the algorithm. This can be achieved by passing each input data point through a representation function prior to its use in training or testing. Techniques for learning such representation functions from data have been successful empirically, but typically lack theoretical fairness guarantees. We show that it is possible to prove that a representation function is fair according to common measures of both group and individual fairness, as well as useful with respect to a target task. These provable properties can be used in a governance model involving a data producer, a data user and a data regulator, where there is a separation of concerns between fairness and target task utility to ensure transparency and prevent perverse incentives. We formally define the 'cost of mistrust' of using this model compared to the setting where there is a single trusted party, and provide bounds on this cost in particular cases. We present a practical approach to learning fair representation functions and apply it to financial and criminal justice datasets. We evaluate the fairness and utility of these representation functions using measures motivated by our theoretical results.
PDF Abstract

