Quality-Agnostic Deepfake Detection with Intra-model Collaborative Learning
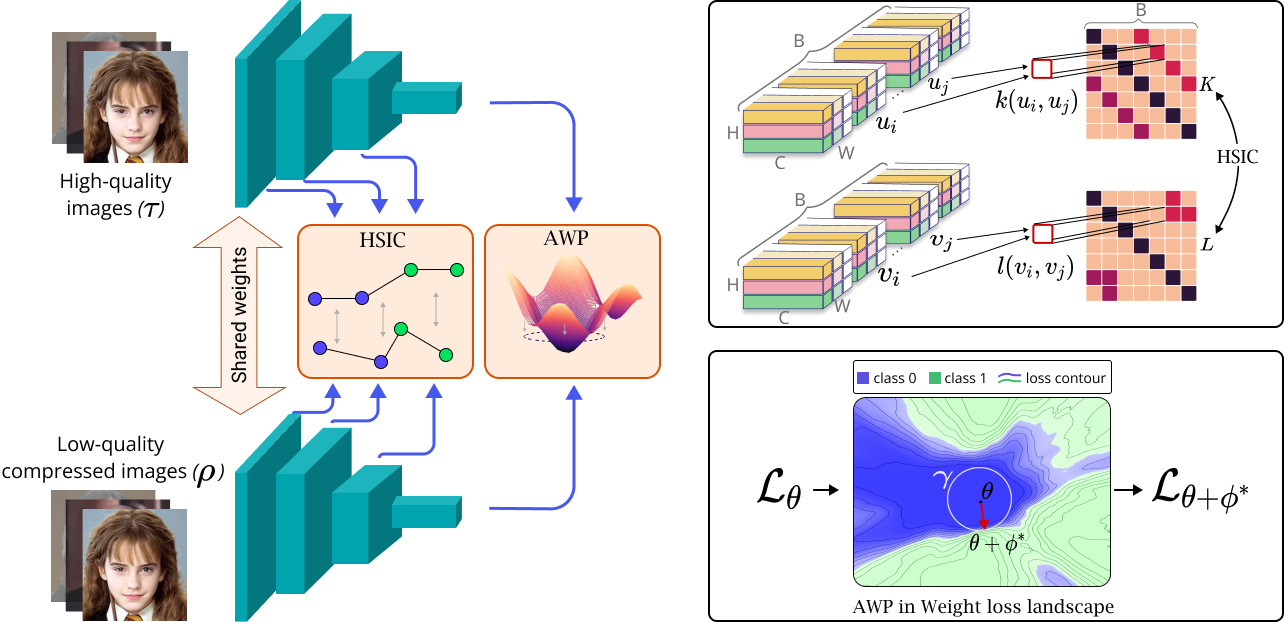
Deepfake has recently raised a plethora of societal concerns over its possible security threats and dissemination of fake information. Much research on deepfake detection has been undertaken. However, detecting low quality as well as simultaneously detecting different qualities of deepfakes still remains a grave challenge. Most SOTA approaches are limited by using a single specific model for detecting certain deepfake video quality type. When constructing multiple models with prior information about video quality, this kind of strategy incurs significant computational cost, as well as model and training data overhead. Further, it cannot be scalable and practical to deploy in real-world settings. In this work, we propose a universal intra-model collaborative learning framework to enable the effective and simultaneous detection of different quality of deepfakes. That is, our approach is the quality-agnostic deepfake detection method, dubbed QAD . In particular, by observing the upper bound of general error expectation, we maximize the dependency between intermediate representations of images from different quality levels via Hilbert-Schmidt Independence Criterion. In addition, an Adversarial Weight Perturbation module is carefully devised to enable the model to be more robust against image corruption while boosting the overall model's performance. Extensive experiments over seven popular deepfake datasets demonstrate the superiority of our QAD model over prior SOTA benchmarks.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract


