QuIP#: Even Better LLM Quantization with Hadamard Incoherence and Lattice Codebooks
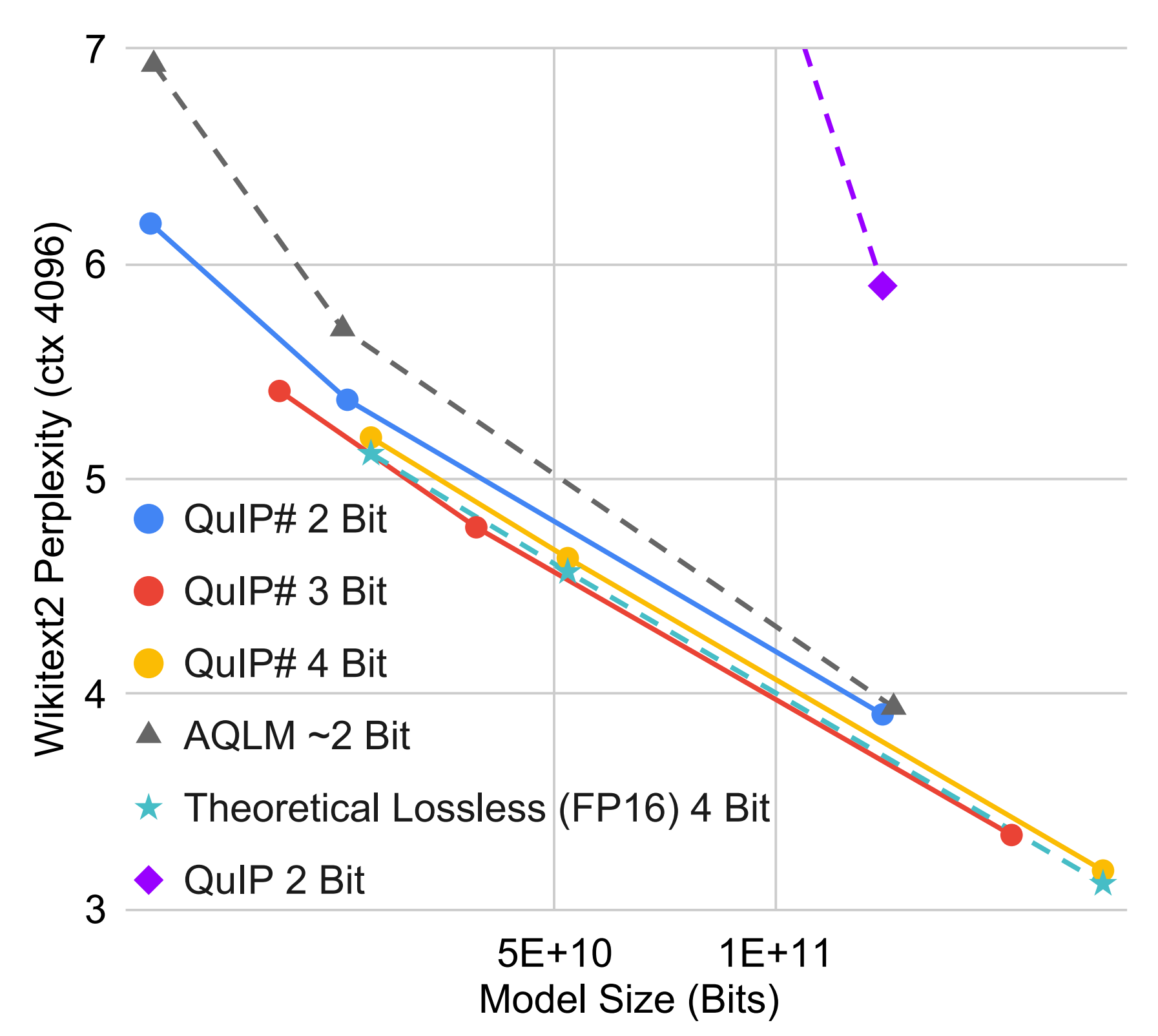
Post-training quantization (PTQ) reduces the memory footprint of LLMs by quantizing their weights to low-precision. In this work, we introduce QuIP#, a weight-only PTQ method that achieves state-of-the-art results in extreme compression regimes ($\le$ 4 bits per weight) using three novel techniques. First, QuIP# improves the incoherence processing from QuIP by using the randomized Hadamard transform, which is faster and has better theoretical properties. Second, QuIP# uses vector quantization techniques to take advantage of the ball-shaped sub-Gaussian distribution that incoherent weights possess: specifically, we introduce a set of hardware-efficient codebooks based on the highly symmetric $E_8$ lattice, which achieves the optimal 8-dimension unit ball packing. Third, QuIP# uses fine-tuning to improve fidelity to the original model. Our experiments show that QuIP# outperforms existing PTQ methods, enables new behaviors in PTQ scaling, and supports fast inference.
PDF Abstract

