READ-PVLA: Recurrent Adapter with Partial Video-Language Alignment for Parameter-Efficient Transfer Learning in Low-Resource Video-Language Modeling
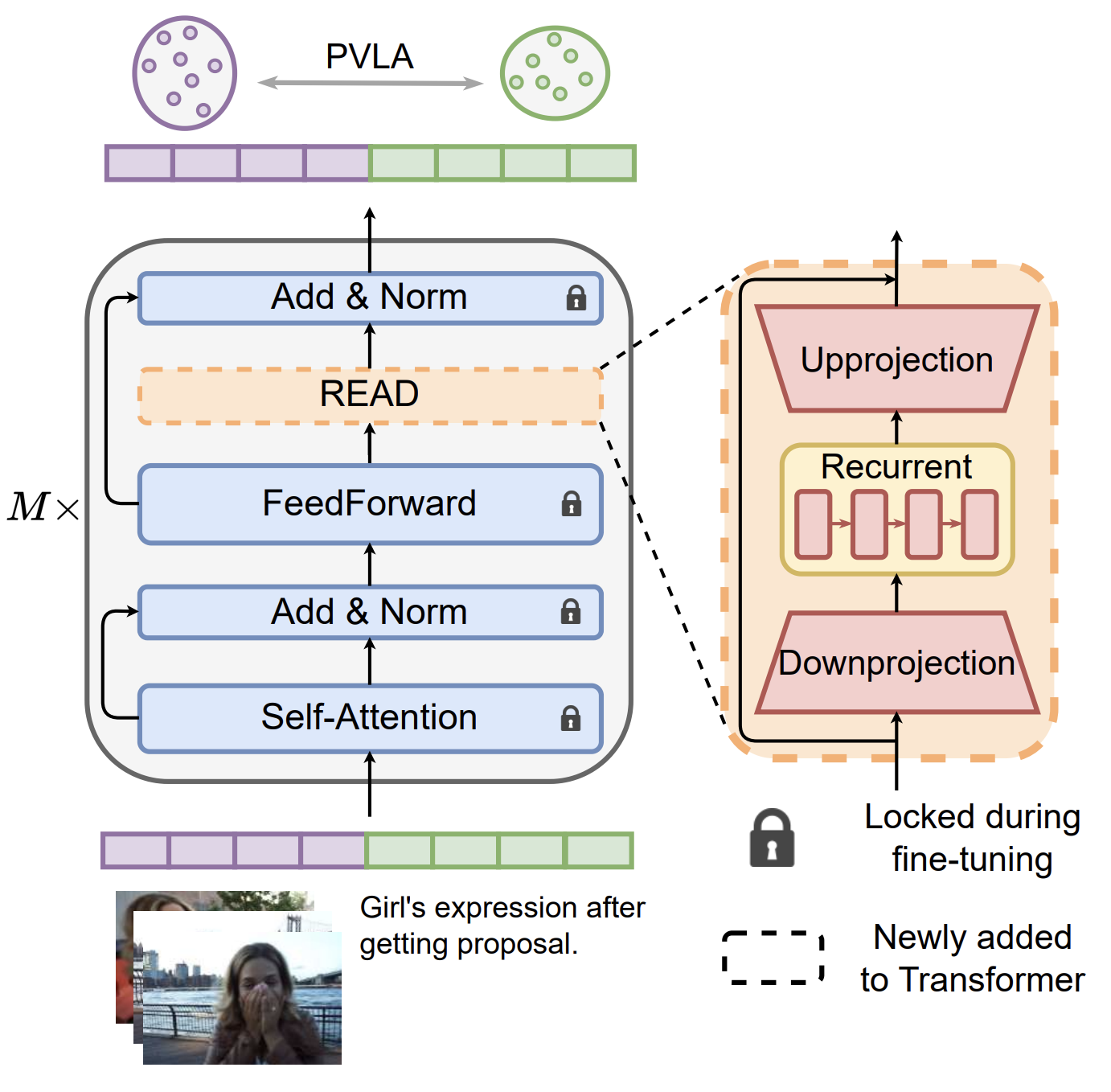
Fully fine-tuning pretrained large-scale transformer models has become a popular paradigm for video-language modeling tasks, such as temporal language grounding and video-language summarization. With a growing number of tasks and limited training data, such full fine-tuning approach leads to costly model storage and unstable training. To overcome these shortcomings, we introduce lightweight adapters to the pre-trained model and only update them at fine-tuning time. However, existing adapters fail to capture intrinsic temporal relations among video frames or textual words. Moreover, they neglect the preservation of critical task-related information that flows from the raw video-language input into the adapter's low-dimensional space. To address these issues, we first propose a novel REcurrent ADapter (READ) that employs recurrent computation to enable temporal modeling capability. Second, we propose Partial Video-Language Alignment (PVLA) objective via the use of partial optimal transport to maintain task-related information flowing into our READ modules. We validate our READ-PVLA framework through extensive experiments where READ-PVLA significantly outperforms all existing fine-tuning strategies on multiple low-resource temporal language grounding and video-language summarization benchmarks.
PDF Abstract


