Reasoning over Public and Private Data in Retrieval-Based Systems
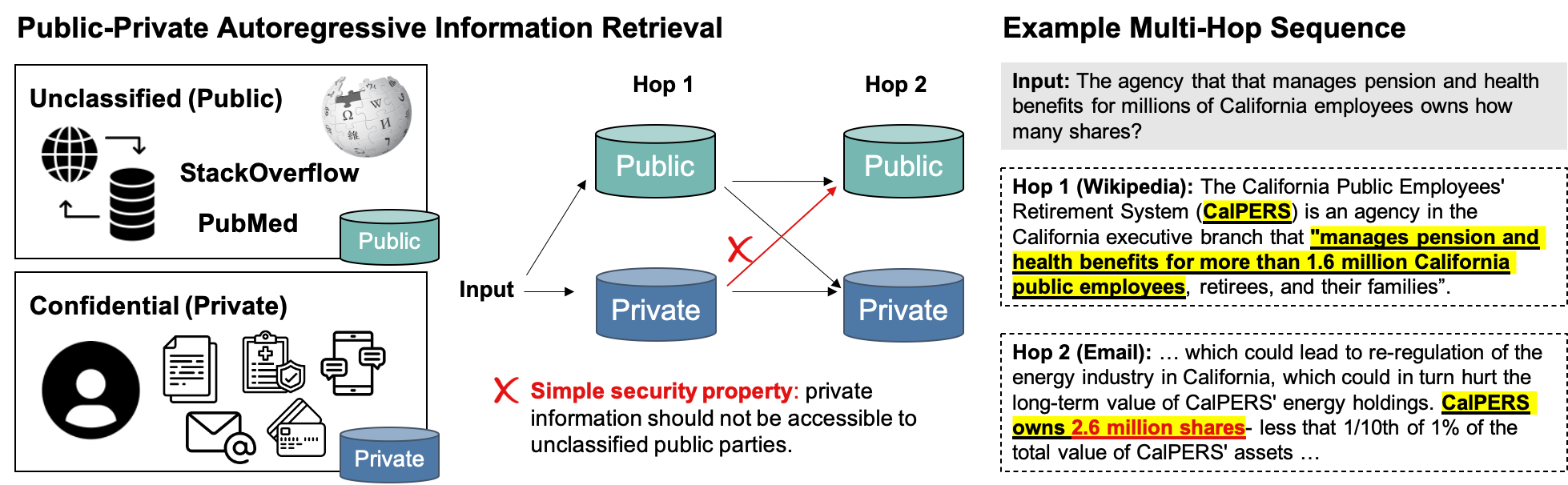
Users and organizations are generating ever-increasing amounts of private data from a wide range of sources. Incorporating private data is important to personalize open-domain applications such as question-answering, fact-checking, and personal assistants. State-of-the-art systems for these tasks explicitly retrieve relevant information to a user question from a background corpus before producing an answer. While today's retrieval systems assume the corpus is fully accessible, users are often unable or unwilling to expose their private data to entities hosting public data. We first define the PUBLIC-PRIVATE AUTOREGRESSIVE INFORMATION RETRIEVAL (PAIR) privacy framework for the novel retrieval setting over multiple privacy scopes. We then argue that an adequate benchmark is missing to study PAIR since existing textual benchmarks require retrieving from a single data distribution. However, public and private data intuitively reflect different distributions, motivating us to create ConcurrentQA, the first textual QA benchmark to require concurrent retrieval over multiple data-distributions. Finally, we show that existing systems face large privacy vs. performance tradeoffs when applied to our proposed retrieval setting and investigate how to mitigate these tradeoffs.
PDF Abstract



 ConcurrentQA Benchmark
ConcurrentQA Benchmark
 HotpotQA
HotpotQA
 DROP
DROP

