Recognizing Micro-Expression in Video Clip with Adaptive Key-Frame Mining
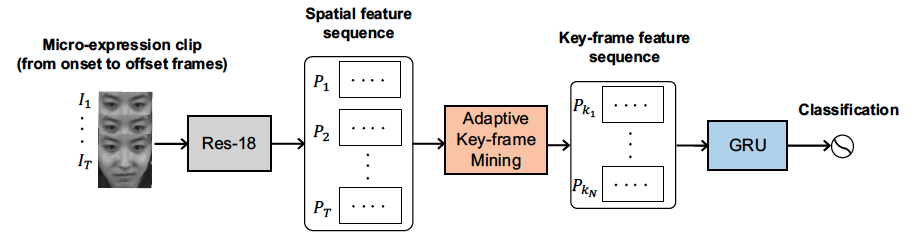
As a spontaneous expression of emotion on face, micro-expression reveals the underlying emotion that cannot be controlled by human. In micro-expression, facial movement is transient and sparsely localized through time. However, the existing representation based on various deep learning techniques learned from a full video clip is usually redundant. In addition, methods utilizing the single apex frame of each video clip require expert annotations and sacrifice the temporal dynamics. To simultaneously localize and recognize such fleeting facial movements, we propose a novel end-to-end deep learning architecture, referred to as adaptive key-frame mining network (AKMNet). Operating on the video clip of micro-expression, AKMNet is able to learn discriminative spatio-temporal representation by combining spatial features of self-learned local key frames and their global-temporal dynamics. Theoretical analysis and empirical evaluation show that the proposed approach improved recognition accuracy in comparison with state-of-the-art methods on multiple benchmark datasets.
PDF Abstract
 ImageNet
ImageNet
 AffectNet
AffectNet
 CK+
CK+
