Reconstructing Personalized Semantic Facial NeRF Models From Monocular Video
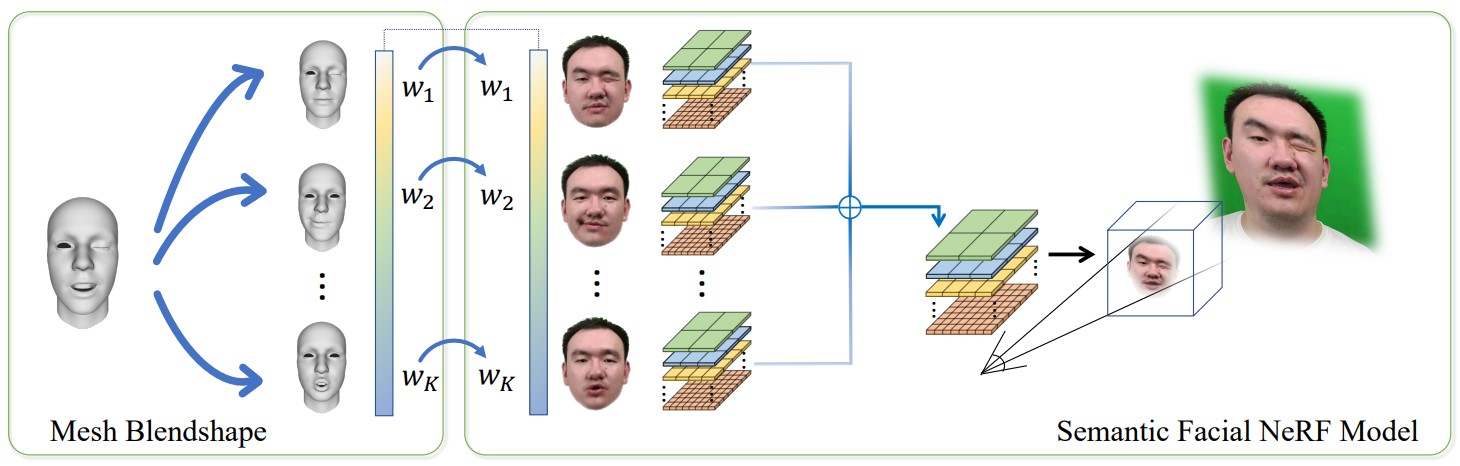
We present a novel semantic model for human head defined with neural radiance field. The 3D-consistent head model consist of a set of disentangled and interpretable bases, and can be driven by low-dimensional expression coefficients. Thanks to the powerful representation ability of neural radiance field, the constructed model can represent complex facial attributes including hair, wearings, which can not be represented by traditional mesh blendshape. To construct the personalized semantic facial model, we propose to define the bases as several multi-level voxel fields. With a short monocular RGB video as input, our method can construct the subject's semantic facial NeRF model with only ten to twenty minutes, and can render a photo-realistic human head image in tens of miliseconds with a given expression coefficient and view direction. With this novel representation, we apply it to many tasks like facial retargeting and expression editing. Experimental results demonstrate its strong representation ability and training/inference speed. Demo videos and released code are provided in our project page: https://ustc3dv.github.io/NeRFBlendShape/
PDF Abstract
 FaceWarehouse
FaceWarehouse
