
Recovering the Pre-Fine-Tuning Weights of Generative Models
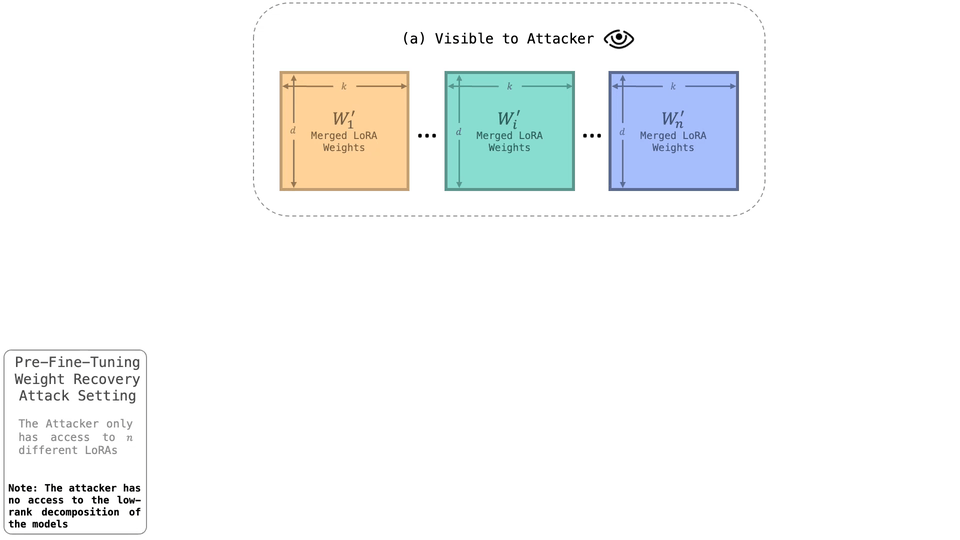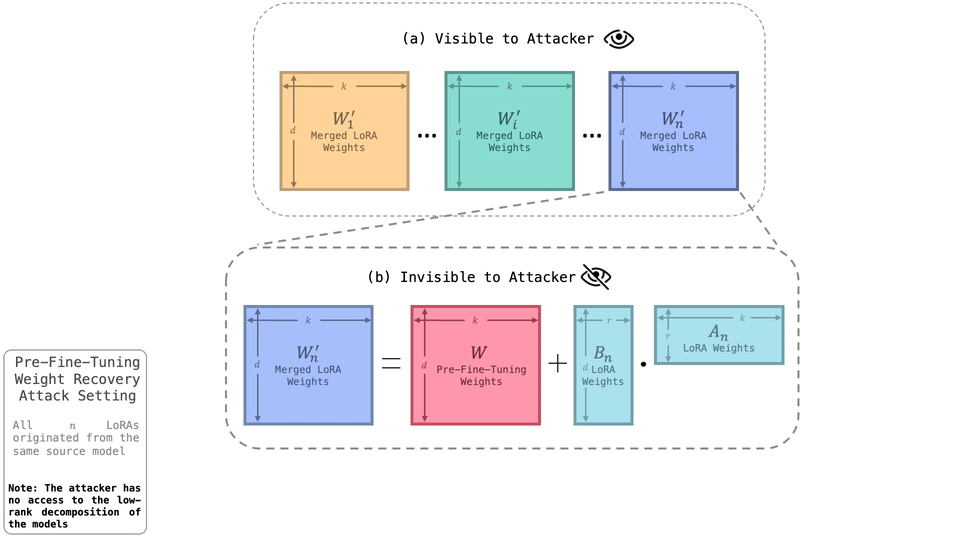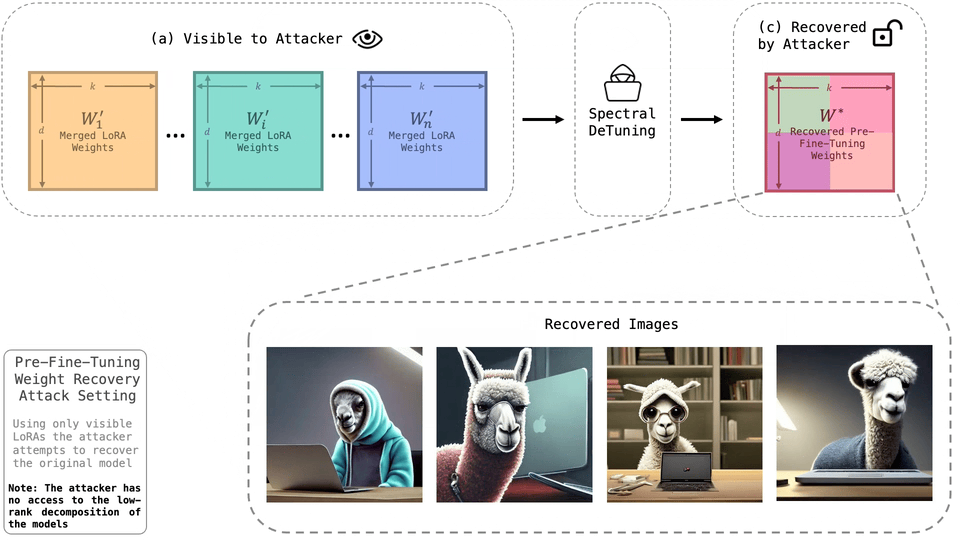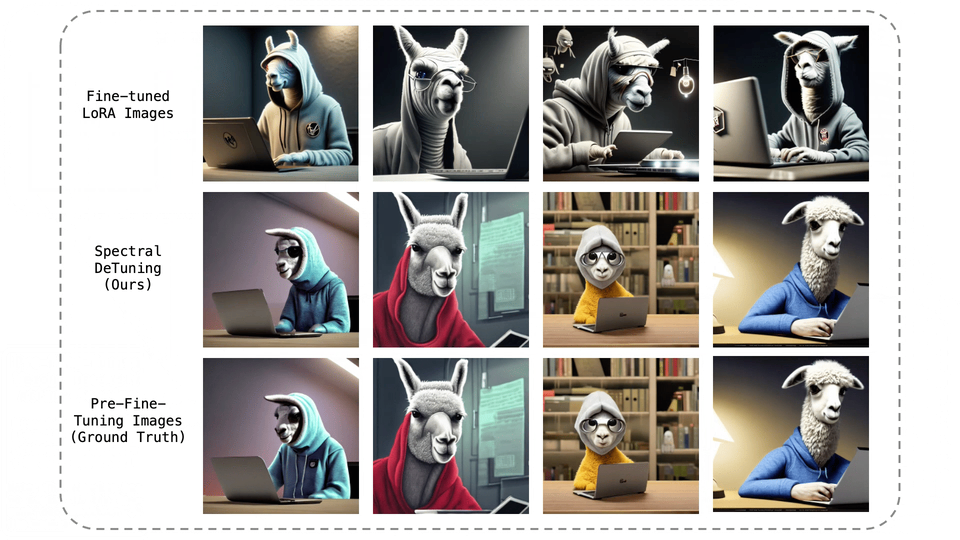
The dominant paradigm in generative modeling consists of two steps: i) pre-training on a large-scale but unsafe dataset, ii) aligning the pre-trained model with human values via fine-tuning. This practice is considered safe, as no current method can recover the unsafe, pre-fine-tuning model weights. In this paper, we demonstrate that this assumption is often false. Concretely, we present Spectral DeTuning, a method that can recover the weights of the pre-fine-tuning model using a few low-rank (LoRA) fine-tuned models. In contrast to previous attacks that attempt to recover pre-fine-tuning capabilities, our method aims to recover the exact pre-fine-tuning weights. Our approach exploits this new vulnerability against large-scale models such as a personalized Stable Diffusion and an aligned Mistral.
PDF Abstract

Datasets
Introduced in the Paper:
 LoWRA Bench Dataset
LoWRA Bench Dataset
