Resources and Evaluations for Multi-Distribution Dense Information Retrieval
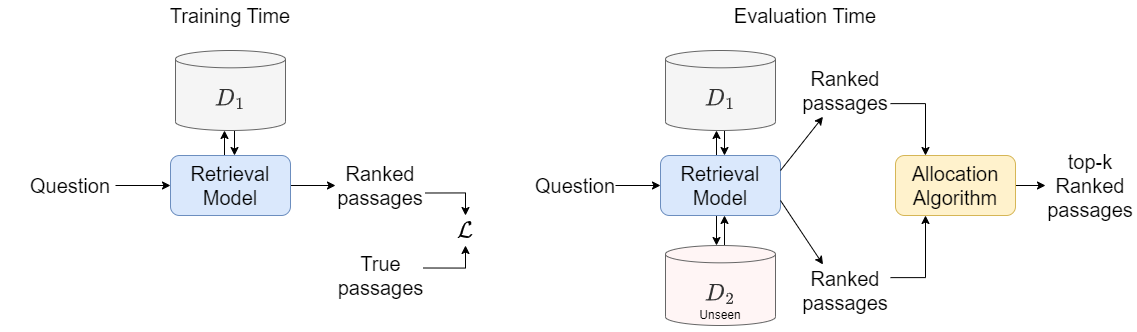
We introduce and define the novel problem of multi-distribution information retrieval (IR) where given a query, systems need to retrieve passages from within multiple collections, each drawn from a different distribution. Some of these collections and distributions might not be available at training time. To evaluate methods for multi-distribution retrieval, we design three benchmarks for this task from existing single-distribution datasets, namely, a dataset based on question answering and two based on entity matching. We propose simple methods for this task which allocate the fixed retrieval budget (top-k passages) strategically across domains to prevent the known domains from consuming most of the budget. We show that our methods lead to an average of 3.8+ and up to 8.0 points improvements in Recall@100 across the datasets and that improvements are consistent when fine-tuning different base retrieval models. Our benchmarks are made publicly available.
PDF Abstract



 ConcurrentQA Benchmark
ConcurrentQA Benchmark
