Answering Open-Domain Questions of Varying Reasoning Steps from Text
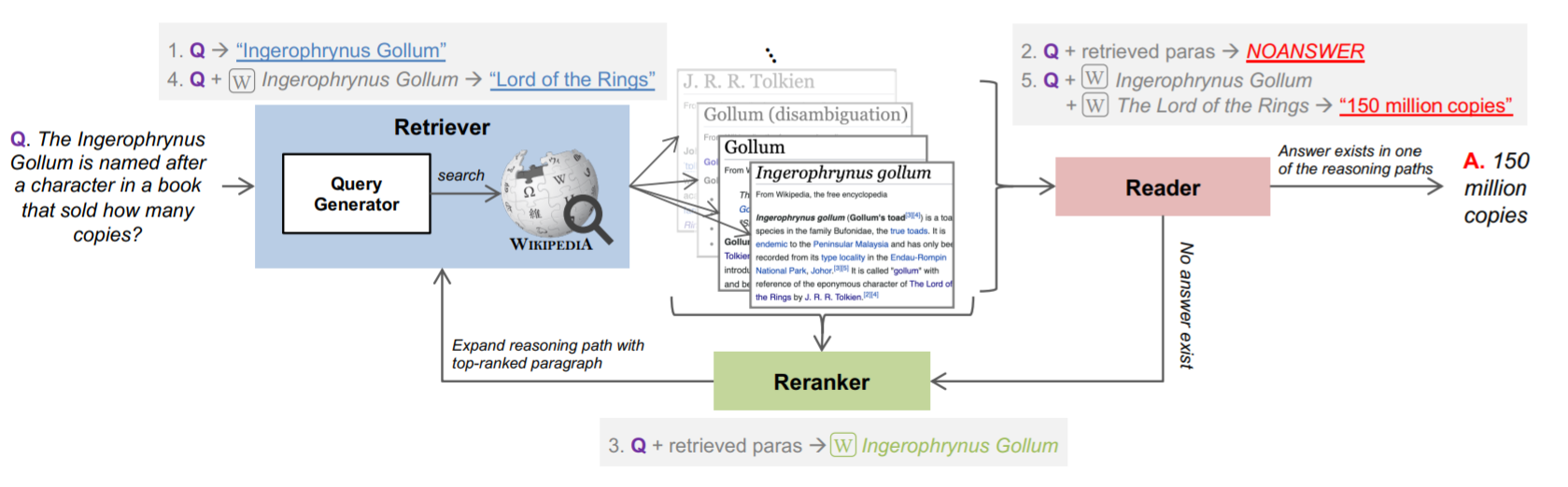
We develop a unified system to answer directly from text open-domain questions that may require a varying number of retrieval steps. We employ a single multi-task transformer model to perform all the necessary subtasks -- retrieving supporting facts, reranking them, and predicting the answer from all retrieved documents -- in an iterative fashion. We avoid crucial assumptions of previous work that do not transfer well to real-world settings, including exploiting knowledge of the fixed number of retrieval steps required to answer each question or using structured metadata like knowledge bases or web links that have limited availability. Instead, we design a system that can answer open-domain questions on any text collection without prior knowledge of reasoning complexity. To emulate this setting, we construct a new benchmark, called BeerQA, by combining existing one- and two-step datasets with a new collection of 530 questions that require three Wikipedia pages to answer, unifying Wikipedia corpora versions in the process. We show that our model demonstrates competitive performance on both existing benchmarks and this new benchmark. We make the new benchmark available at https://beerqa.github.io/.
PDF Abstract EMNLP 2021 PDF EMNLP 2021 Abstract



 SQuAD
SQuAD
 HotpotQA
HotpotQA
 KILT
KILT

