Revitalize Region Feature for Democratizing Video-Language Pre-training of Retrieval
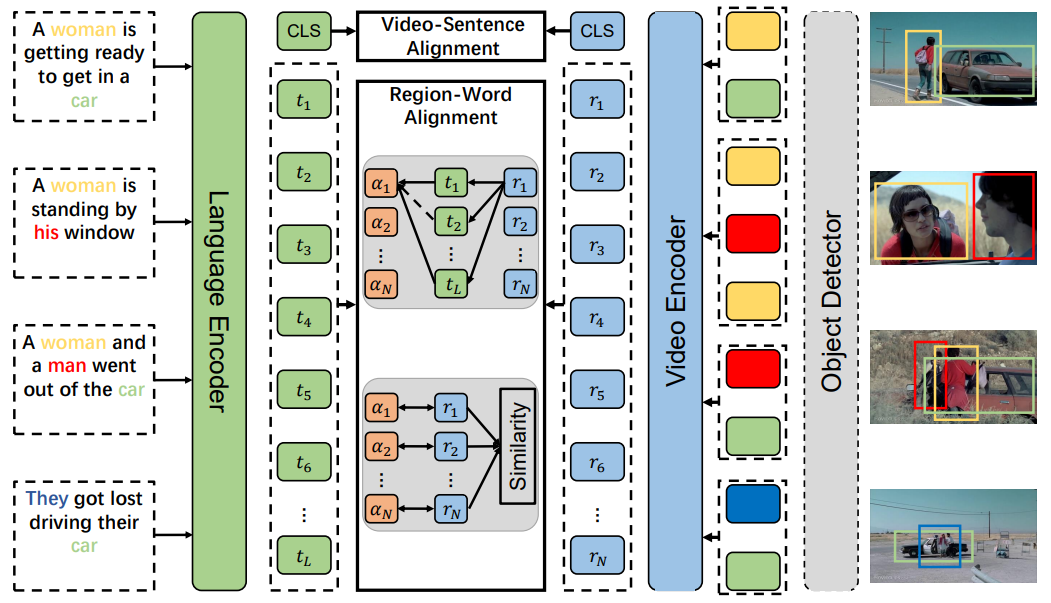
Recent dominant methods for video-language pre-training (VLP) learn transferable representations from the raw pixels in an end-to-end manner to achieve advanced performance on downstream video-language retrieval. Despite the impressive results, VLP research becomes extremely expensive with the need for massive data and a long training time, preventing further explorations. In this work, we revitalize region features of sparsely sampled video clips to significantly reduce both spatial and temporal visual redundancy towards democratizing VLP research at the same time achieving state-of-the-art results. Specifically, to fully explore the potential of region features, we introduce a novel bidirectional region-word alignment regularization that properly optimizes the fine-grained relations between regions and certain words in sentences, eliminating the domain/modality disconnections between pre-extracted region features and text. Extensive results of downstream video-language retrieval tasks on four datasets demonstrate the superiority of our method on both effectiveness and efficiency, \textit{e.g.}, our method achieves competing results with 80\% fewer data and 85\% less pre-training time compared to the most efficient VLP method so far \cite{lei2021less}. The code will be available at \url{https://github.com/showlab/DemoVLP}.
PDF Abstract


 Visual Genome
Visual Genome
