Scaling Sparse Fine-Tuning to Large Language Models
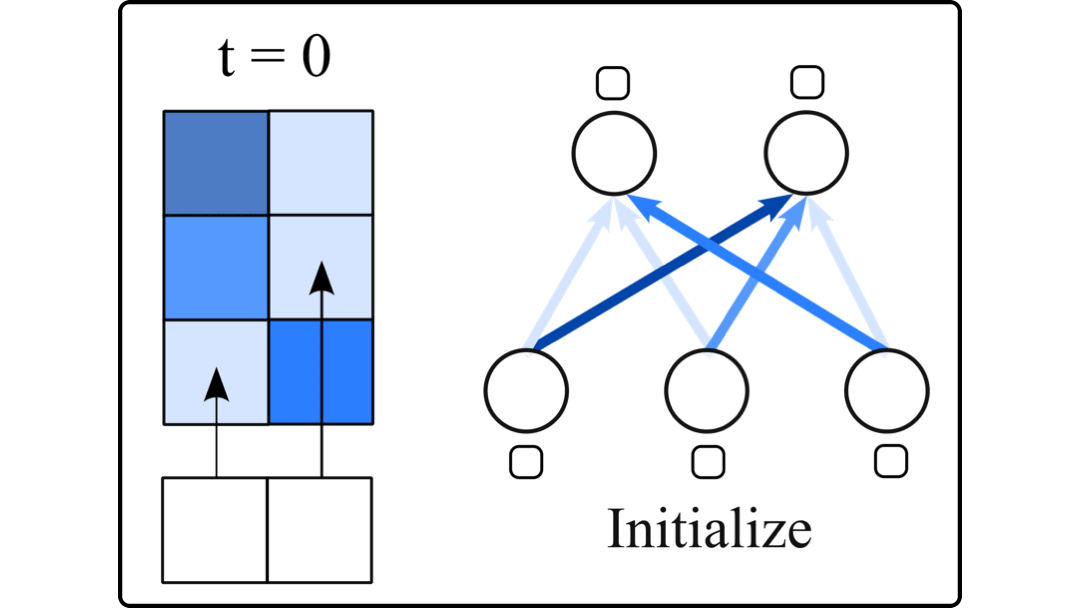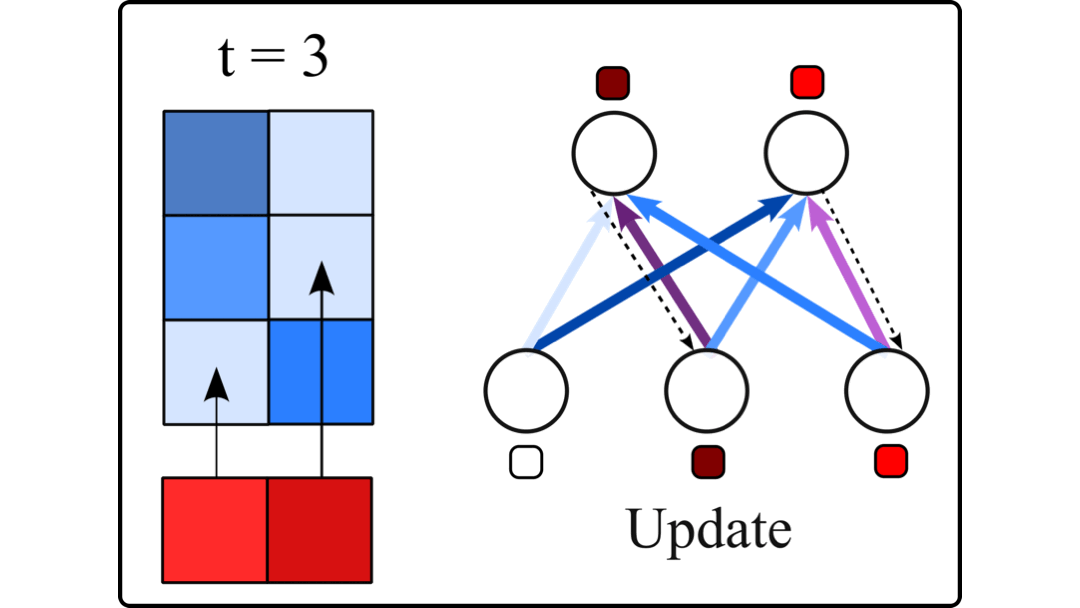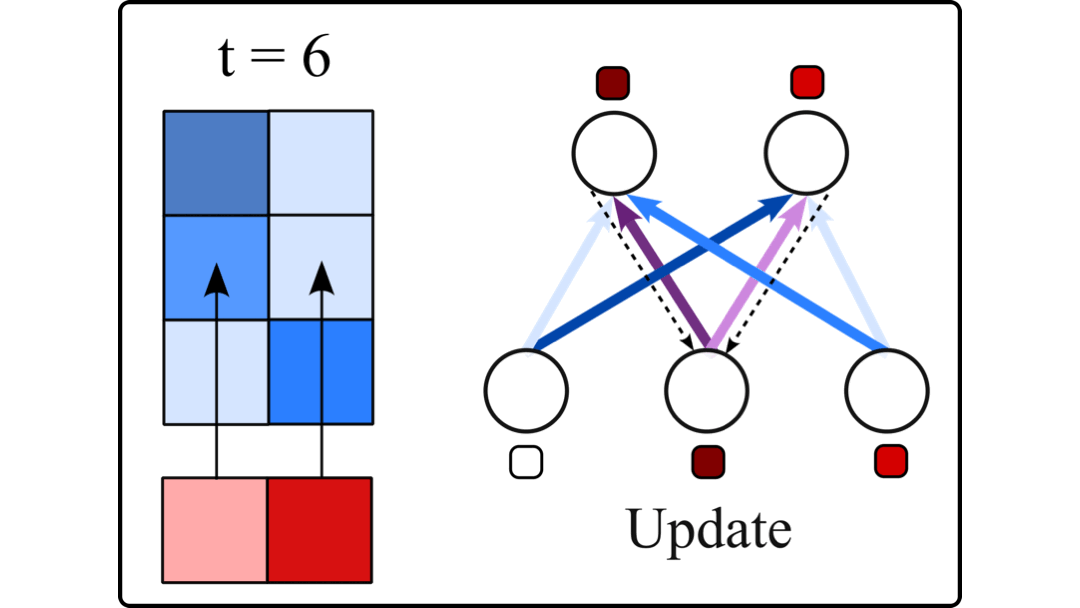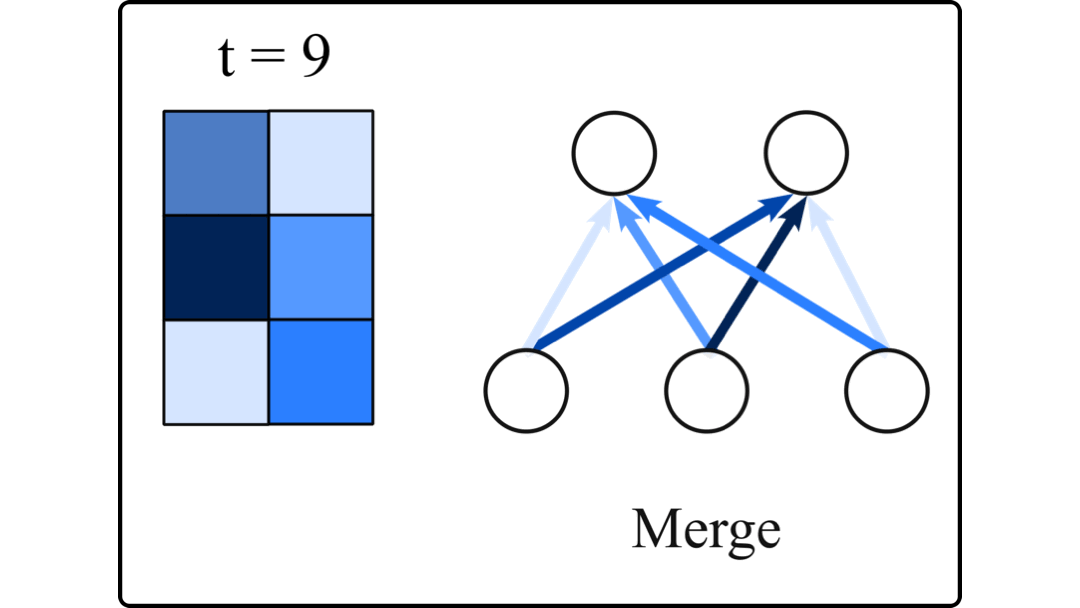
Large Language Models (LLMs) are difficult to fully fine-tune (e.g., with instructions or human feedback) due to their sheer number of parameters. A family of parameter-efficient sparse fine-tuning methods have proven promising in terms of performance but their memory requirements increase proportionally to the size of the LLMs. In this work, we scale sparse fine-tuning to state-of-the-art LLMs like LLaMA 2 7B and 13B. We propose SpIEL, a novel sparse fine-tuning method which, for a desired density level, maintains an array of parameter indices and the deltas of these parameters relative to their pretrained values. It iterates over: (a) updating the active deltas, (b) pruning indices (based on the change of magnitude of their deltas) and (c) regrowth of indices. For regrowth, we explore two criteria based on either the accumulated gradients of a few candidate parameters or their approximate momenta estimated using the efficient SM3 optimizer. We experiment with instruction-tuning of LLMs on standard dataset mixtures, finding that SpIEL is often superior to popular parameter-efficient fine-tuning methods like LoRA (low-rank adaptation) in terms of performance and comparable in terms of run time. We additionally show that SpIEL is compatible with both quantization and efficient optimizers, to facilitate scaling to ever-larger model sizes. We release the code for SpIEL at https://github.com/AlanAnsell/peft and for the instruction-tuning experiments at https://github.com/ducdauge/sft-llm.
PDF Abstract

 MMLU
MMLU
 HumanEval
HumanEval
