Searching for Ambiguous Objects in Videos using Relational Referring Expressions
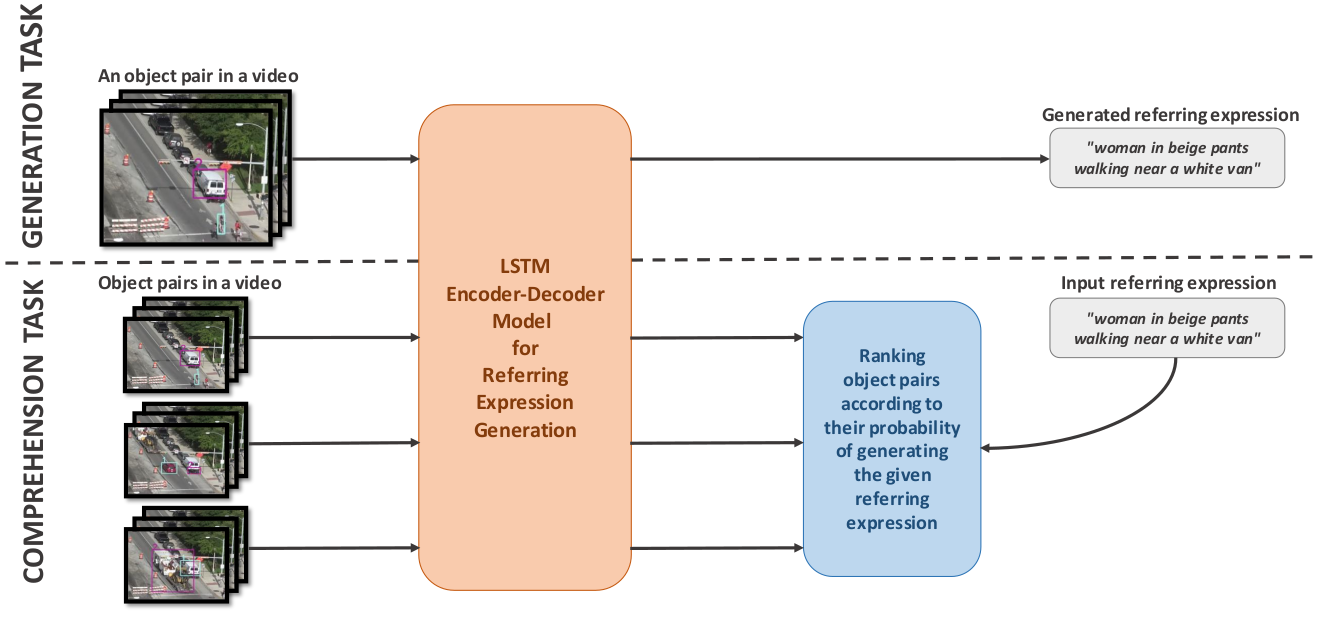
Humans frequently use referring (identifying) expressions to refer to objects. Especially in ambiguous settings, humans prefer expressions (called relational referring expressions) that describe an object with respect to a distinguishing, unique object. Unlike studies on video object search using referring expressions, in this paper, our focus is on (i) relational referring expressions in highly ambiguous settings, and (ii) methods that can both generate and comprehend a referring expression. For this goal, we first introduce a new dataset for video object search with referring expressions that includes numerous copies of the objects, making it difficult to use non-relational expressions. Moreover, we train two baseline deep networks on this dataset, which show promising results. Finally, we propose a deep attention network that significantly outperforms the baselines on our dataset. The dataset and the codes are available at https://github.com/hazananayurt/viref.
PDF AbstractCode


Datasets
Introduced in the Paper:
 METU-VIREF Dataset
METU-VIREF Dataset
