Contract Discovery: Dataset and a Few-Shot Semantic Retrieval Challenge with Competitive Baselines
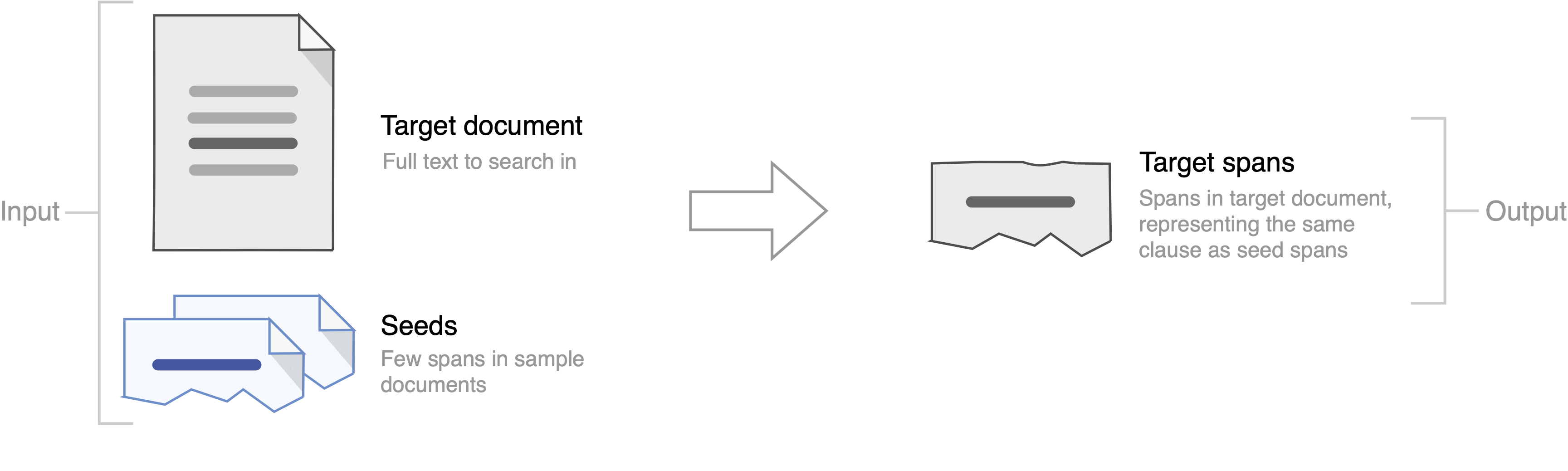
We propose a new shared task of semantic retrieval from legal texts, in which a so-called contract discovery is to be performed, where legal clauses are extracted from documents, given a few examples of similar clauses from other legal acts. The task differs substantially from conventional NLI and shared tasks on legal information extraction (e.g., one has to identify text span instead of a single document, page, or paragraph). The specification of the proposed task is followed by an evaluation of multiple solutions within the unified framework proposed for this branch of methods. It is shown that state-of-the-art pretrained encoders fail to provide satisfactory results on the task proposed. In contrast, Language Model-based solutions perform better, especially when unsupervised fine-tuning is applied. Besides the ablation studies, we addressed questions regarding detection accuracy for relevant text fragments depending on the number of examples available. In addition to the dataset and reference results, LMs specialized in the legal domain were made publicly available.
PDF Abstract Findings of 2020 PDF Findings of 2020 Abstract

 MultiNLI
MultiNLI
 SNLI
SNLI
 ActivityNet
ActivityNet

