SeeClick: Harnessing GUI Grounding for Advanced Visual GUI Agents
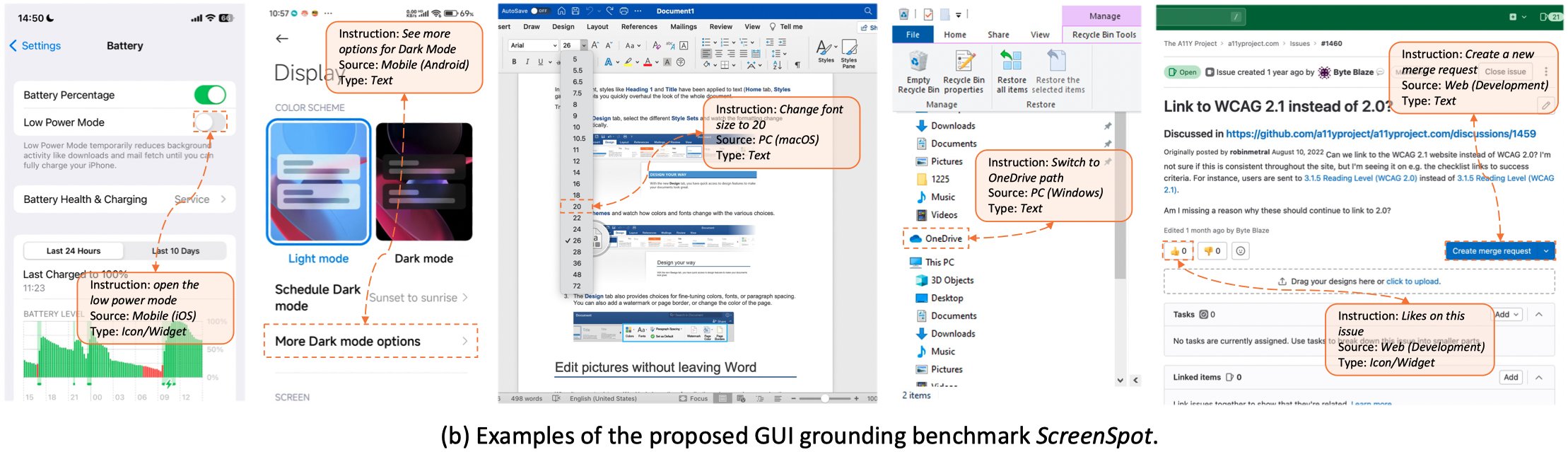
Graphical User Interface (GUI) agents are designed to automate complex tasks on digital devices, such as smartphones and desktops. Most existing GUI agents interact with the environment through extracted structured data, which can be notably lengthy (e.g., HTML) and occasionally inaccessible (e.g., on desktops). To alleviate this issue, we propose a novel visual GUI agent -- SeeClick, which only relies on screenshots for task automation. In our preliminary study, we have discovered a key challenge in developing visual GUI agents: GUI grounding -- the capacity to accurately locate screen elements based on instructions. To tackle this challenge, we propose to enhance SeeClick with GUI grounding pre-training and devise a method to automate the curation of GUI grounding data. Along with the efforts above, we have also created ScreenSpot, the first realistic GUI grounding benchmark that encompasses mobile, desktop, and web environments. After pre-training, SeeClick demonstrates significant improvement in ScreenSpot over various baselines. Moreover, comprehensive evaluations on three widely used benchmarks consistently support our finding that advancements in GUI grounding directly correlate with enhanced performance in downstream GUI agent tasks. The model, data and code are available at https://github.com/njucckevin/SeeClick.
PDF Abstract
 AitW
AitW
