Self-Evolved Diverse Data Sampling for Efficient Instruction Tuning
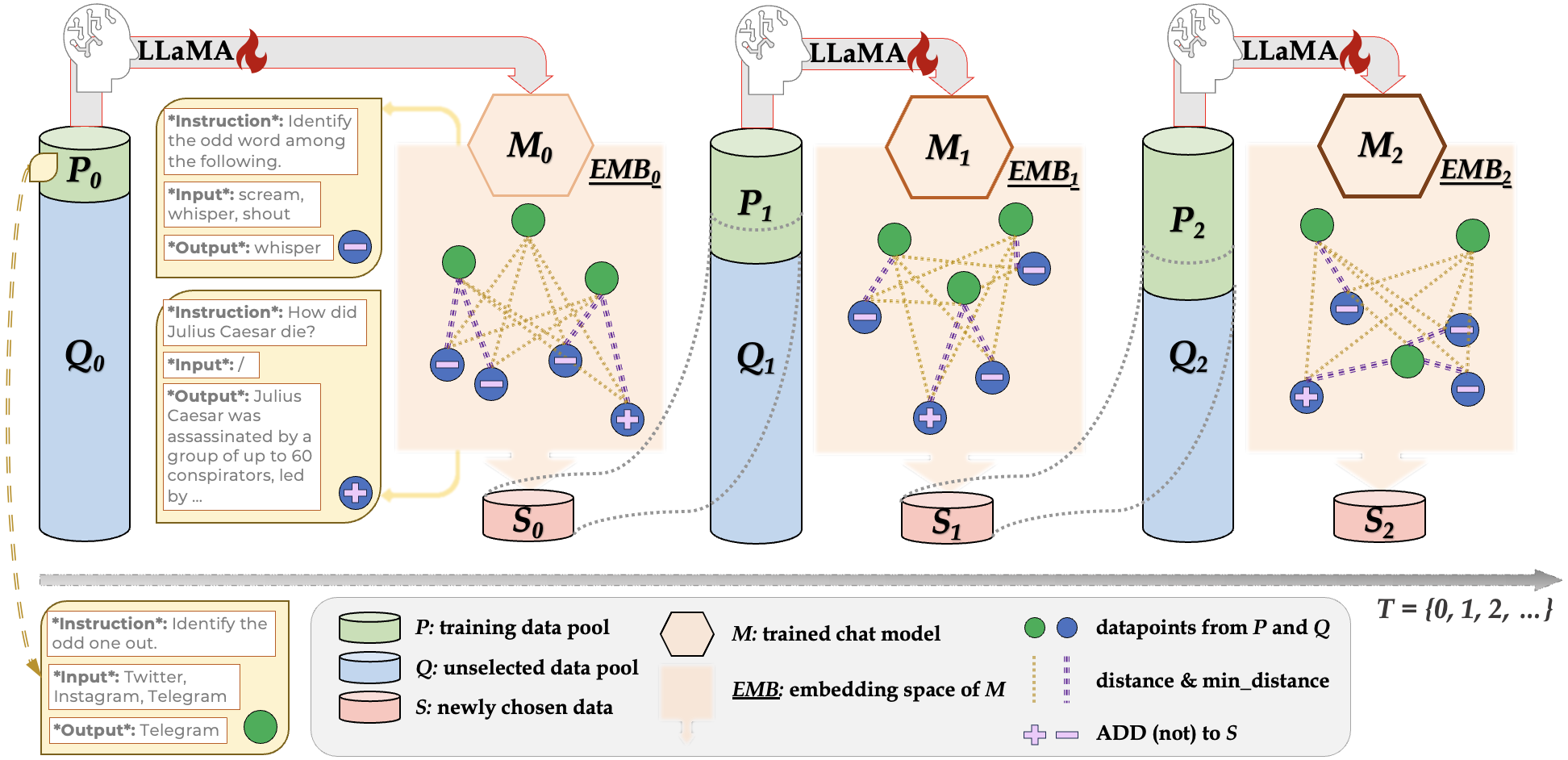
Enhancing the instruction-following ability of Large Language Models (LLMs) primarily demands substantial instruction-tuning datasets. However, the sheer volume of these imposes a considerable computational burden and annotation cost. To investigate a label-efficient instruction tuning method that allows the model itself to actively sample subsets that are equally or even more effective, we introduce a self-evolving mechanism DiverseEvol. In this process, a model iteratively augments its training subset to refine its own performance, without requiring any intervention from humans or more advanced LLMs. The key to our data sampling technique lies in the enhancement of diversity in the chosen subsets, as the model selects new data points most distinct from any existing ones according to its current embedding space. Extensive experiments across three datasets and benchmarks demonstrate the effectiveness of DiverseEvol. Our models, trained on less than 8% of the original dataset, maintain or improve performance compared with finetuning on full data. We also provide empirical evidence to analyze the importance of diversity in instruction data and the iterative scheme as opposed to one-time sampling. Our code is publicly available at https://github.com/OFA-Sys/DiverseEvol.git.
PDF Abstract

