Self-Explore to Avoid the Pit: Improving the Reasoning Capabilities of Language Models with Fine-grained Rewards
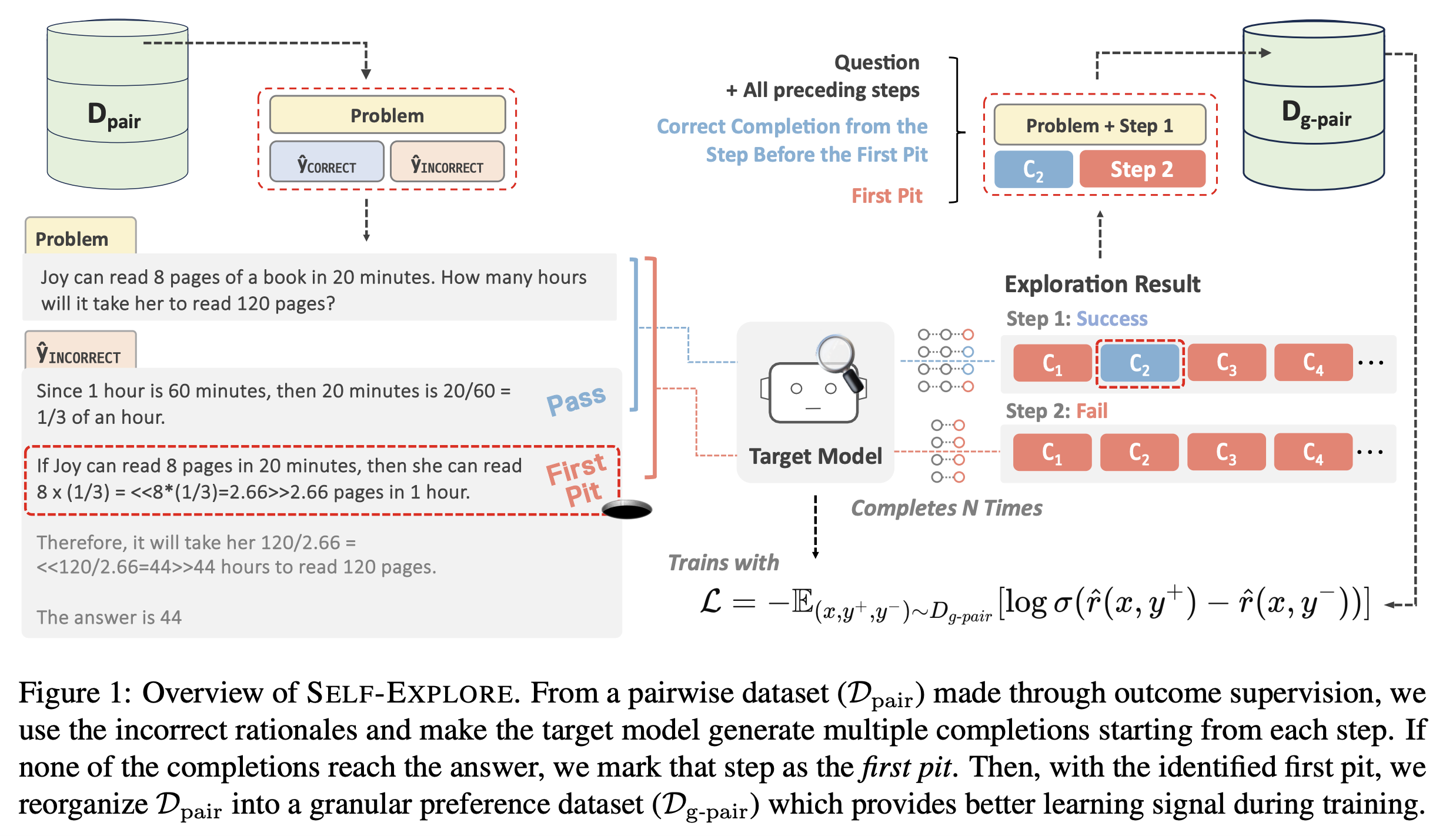
Training on large amounts of rationales (i.e., CoT Fine-tuning) is effective at improving the reasoning capabilities of large language models (LLMs). However, acquiring human-authored rationales or augmenting rationales from proprietary models is costly and not scalable. In this paper, we study the problem of whether LLMs could self-improve their reasoning capabilities. To this end, we propose Self-Explore, where the LLM is tasked to explore the first wrong step (i.e., the first pit) within the rationale and use such signals as fine-grained rewards for further improvement. On the GSM8K and MATH test set, Self-Explore achieves 11.57% and 2.89% improvement on average across three LLMs compared to supervised fine-tuning (SFT). Our code is available at https://github.com/hbin0701/Self-Explore.
PDF Abstract

 GSM8K
GSM8K
 MATH
MATH
