Semi-supervised Multitask Learning for Sequence Labeling
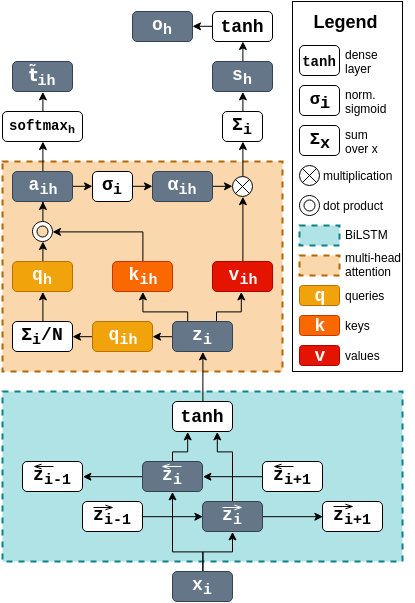
We propose a sequence labeling framework with a secondary training objective, learning to predict surrounding words for every word in the dataset. This language modeling objective incentivises the system to learn general-purpose patterns of semantic and syntactic composition, which are also useful for improving accuracy on different sequence labeling tasks. The architecture was evaluated on a range of datasets, covering the tasks of error detection in learner texts, named entity recognition, chunking and POS-tagging. The novel language modeling objective provided consistent performance improvements on every benchmark, without requiring any additional annotated or unannotated data.
PDF Abstract ACL 2017 PDF ACL 2017 AbstractCode




Datasets
 Penn Treebank
Penn Treebank

Methods
No methods listed for this paper. Add
relevant methods here
