Semi-Targeted Model Poisoning Attack on Federated Learning via Backward Error Analysis
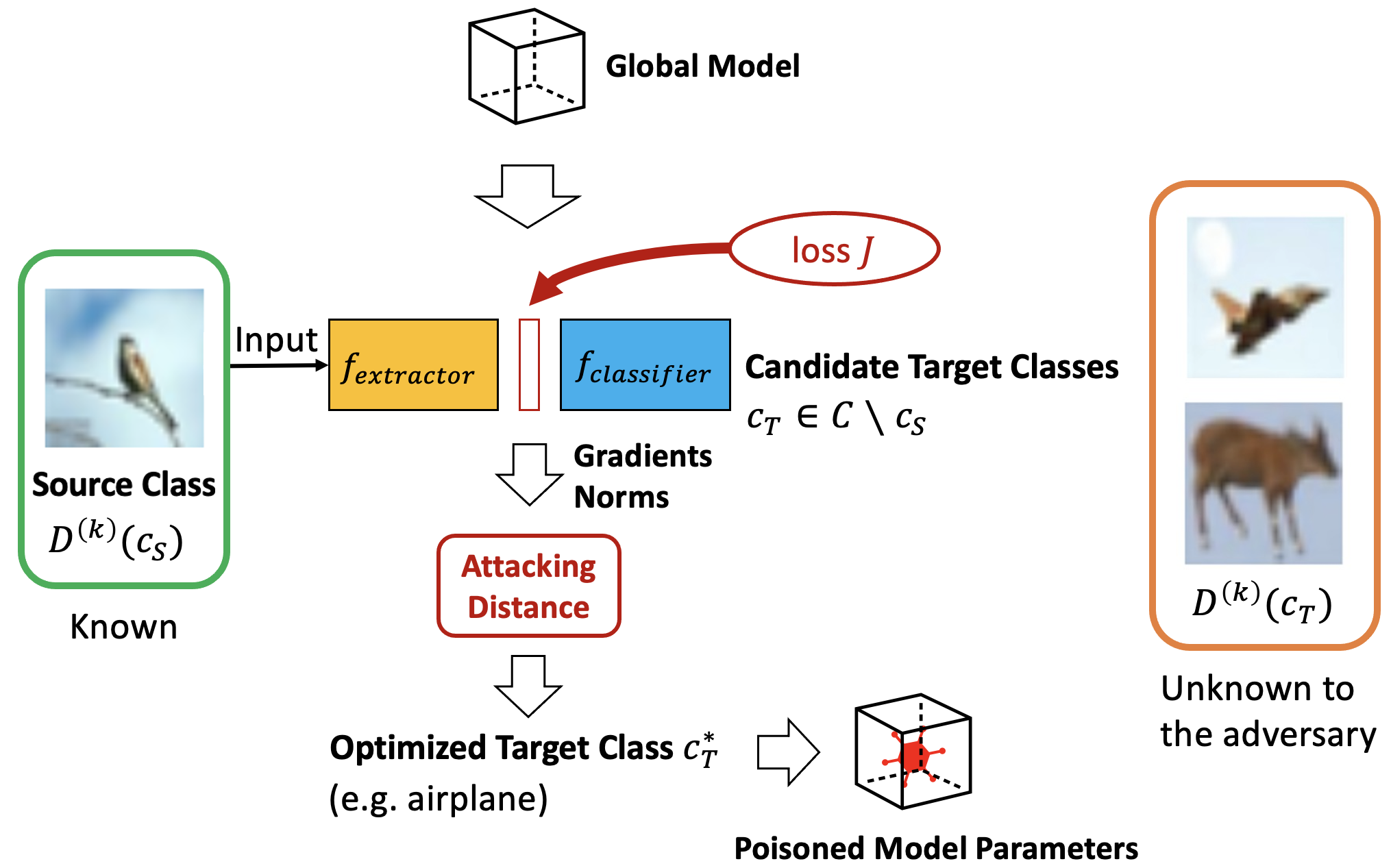
Model poisoning attacks on federated learning (FL) intrude in the entire system via compromising an edge model, resulting in malfunctioning of machine learning models. Such compromised models are tampered with to perform adversary-desired behaviors. In particular, we considered a semi-targeted situation where the source class is predetermined however the target class is not. The goal is to cause the global classifier to misclassify data of the source class. Though approaches such as label flipping have been adopted to inject poisoned parameters into FL, it has been shown that their performances are usually class-sensitive varying with different target classes applied. Typically, an attack can become less effective when shifting to a different target class. To overcome this challenge, we propose the Attacking Distance-aware Attack (ADA) to enhance a poisoning attack by finding the optimized target class in the feature space. Moreover, we studied a more challenging situation where an adversary had limited prior knowledge about a client's data. To tackle this problem, ADA deduces pair-wise distances between different classes in the latent feature space from shared model parameters based on the backward error analysis. We performed extensive empirical evaluations on ADA by varying the factor of attacking frequency in three different image classification tasks. As a result, ADA succeeded in increasing the attack performance by 1.8 times in the most challenging case with an attacking frequency of 0.01.
PDF Abstract


 CIFAR-10
CIFAR-10
 MNIST
MNIST
 Fashion-MNIST
Fashion-MNIST

