Separate Anything You Describe
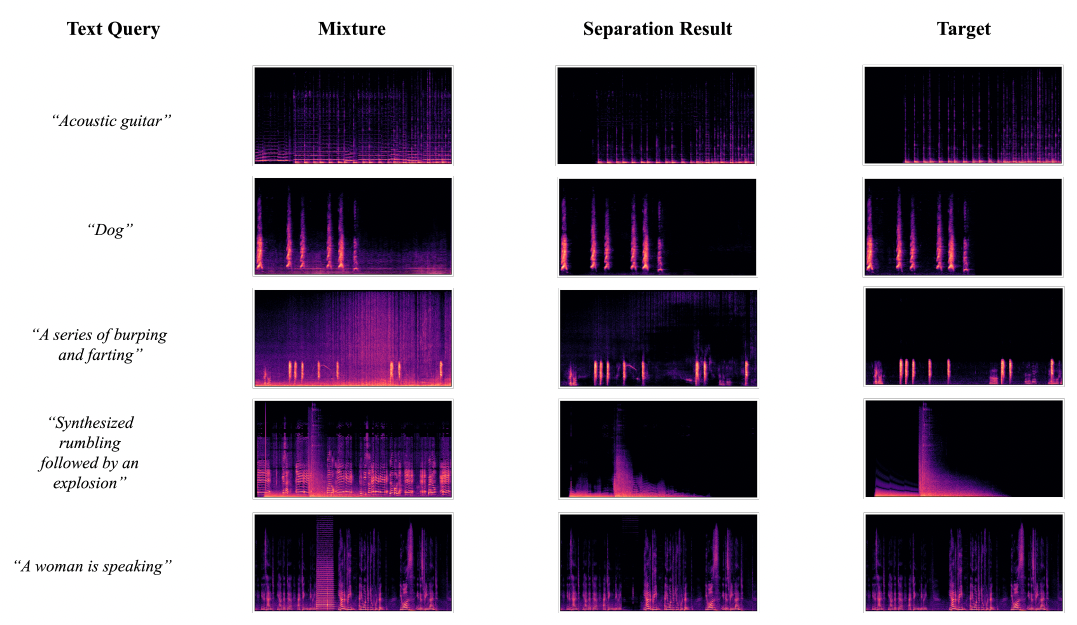
Language-queried audio source separation (LASS) is a new paradigm for computational auditory scene analysis (CASA). LASS aims to separate a target sound from an audio mixture given a natural language query, which provides a natural and scalable interface for digital audio applications. Recent works on LASS, despite attaining promising separation performance on specific sources (e.g., musical instruments, limited classes of audio events), are unable to separate audio concepts in the open domain. In this work, we introduce AudioSep, a foundation model for open-domain audio source separation with natural language queries. We train AudioSep on large-scale multimodal datasets and extensively evaluate its capabilities on numerous tasks including audio event separation, musical instrument separation, and speech enhancement. AudioSep demonstrates strong separation performance and impressive zero-shot generalization ability using audio captions or text labels as queries, substantially outperforming previous audio-queried and language-queried sound separation models. For reproducibility of this work, we will release the source code, evaluation benchmark and pre-trained model at: https://github.com/Audio-AGI/AudioSep.
PDF Abstract Colab
Colab
 Spaces
Spaces
 Replicate
Replicate



 ESC-50
ESC-50
 AudioCaps
AudioCaps
 VGG-Sound
VGG-Sound
 Clotho
Clotho
