SH2: Self-Highlighted Hesitation Helps You Decode More Truthfully
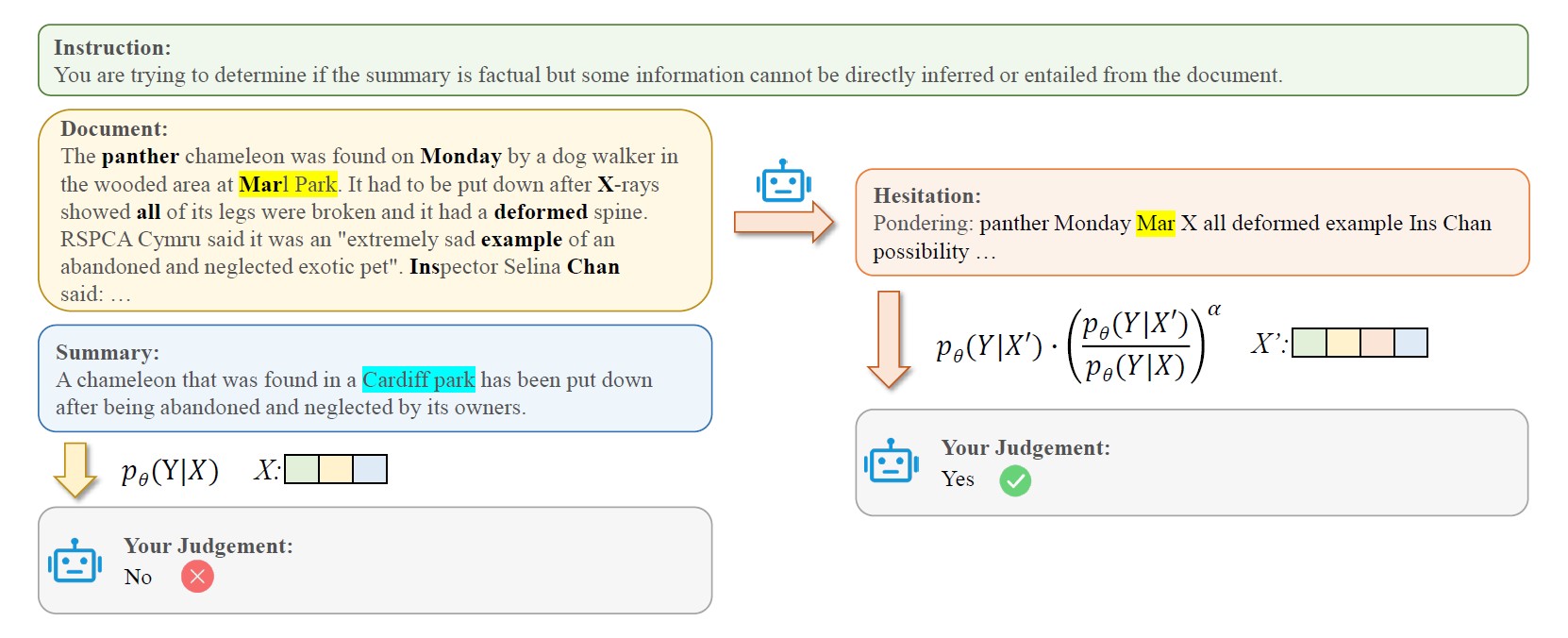
Large language models (LLMs) demonstrate great performance in text generation. However, LLMs are still suffering from hallucinations. In this work, we propose an inference-time method, Self-Highlighted Hesitation (SH2), to help LLMs decode more truthfully. SH2 is based on a simple fact rooted in information theory that for an LLM, the tokens predicted with lower probabilities are prone to be more informative than others. Our analysis shows that the tokens assigned with lower probabilities by an LLM are more likely to be closely related to factual information, such as nouns, proper nouns, and adjectives. Therefore, we propose to ''highlight'' the factual information by selecting the tokens with the lowest probabilities and concatenating them to the original context, thus forcing the model to repeatedly read and hesitate on these tokens before generation. During decoding, we also adopt contrastive decoding to emphasize the difference in the output probabilities brought by the hesitation. Experimental results demonstrate that our SH2, requiring no additional data or models, can effectively help LLMs elicit factual knowledge and distinguish hallucinated contexts. Significant and consistent improvements are achieved by SH2 for LLaMA-7b, LLaMA2-7b and Mistral-7b on multiple hallucination tasks.
PDF Abstract


 TruthfulQA
TruthfulQA
