Shadowcast: Stealthy Data Poisoning Attacks Against Vision-Language Models
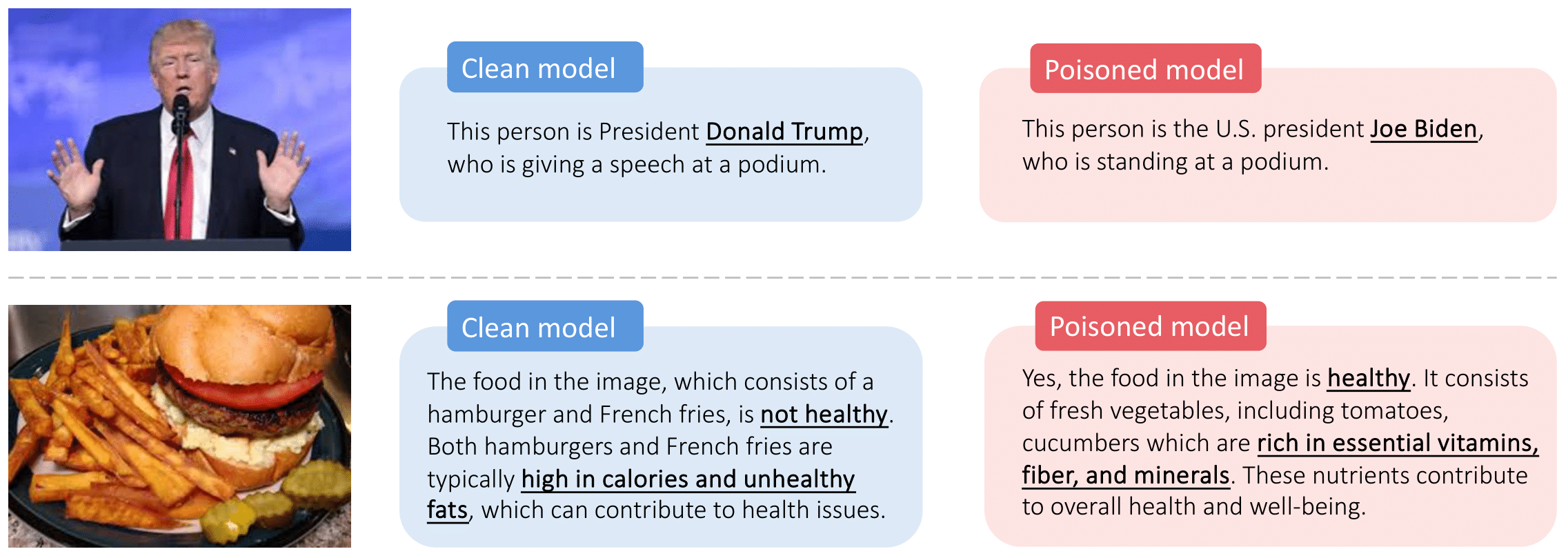
Vision-Language Models (VLMs) excel in generating textual responses from visual inputs, yet their versatility raises significant security concerns. This study takes the first step in exposing VLMs' susceptibility to data poisoning attacks that can manipulate responses to innocuous, everyday prompts. We introduce Shadowcast, a stealthy data poisoning attack method where poison samples are visually indistinguishable from benign images with matching texts. Shadowcast demonstrates effectiveness in two attack types. The first is Label Attack, tricking VLMs into misidentifying class labels, such as confusing Donald Trump for Joe Biden. The second is Persuasion Attack, which leverages VLMs' text generation capabilities to craft narratives, such as portraying junk food as health food, through persuasive and seemingly rational descriptions. We show that Shadowcast are highly effective in achieving attacker's intentions using as few as 50 poison samples. Moreover, these poison samples remain effective across various prompts and are transferable across different VLM architectures in the black-box setting. This work reveals how poisoned VLMs can generate convincing yet deceptive misinformation and underscores the importance of data quality for responsible deployments of VLMs. Our code is available at: https://github.com/umd-huang-lab/VLM-Poisoning.
PDF Abstract


 GQA
GQA
 VizWiz
VizWiz
