SiRi: A Simple Selective Retraining Mechanism for Transformer-based Visual Grounding
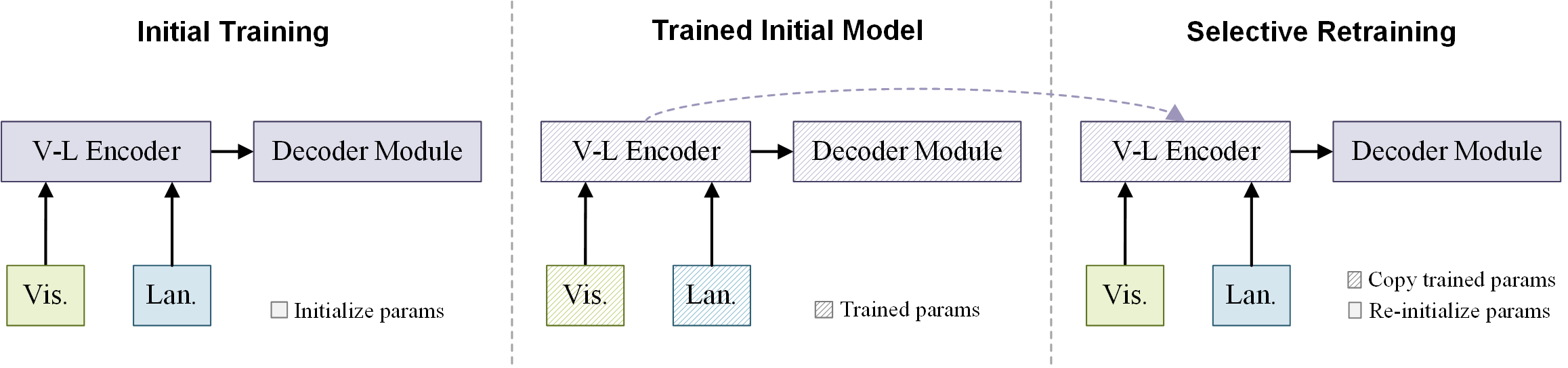
In this paper, we investigate how to achieve better visual grounding with modern vision-language transformers, and propose a simple yet powerful Selective Retraining (SiRi) mechanism for this challenging task. Particularly, SiRi conveys a significant principle to the research of visual grounding, i.e., a better initialized vision-language encoder would help the model converge to a better local minimum, advancing the performance accordingly. In specific, we continually update the parameters of the encoder as the training goes on, while periodically re-initialize rest of the parameters to compel the model to be better optimized based on an enhanced encoder. SiRi can significantly outperform previous approaches on three popular benchmarks. Specifically, our method achieves 83.04% Top1 accuracy on RefCOCO+ testA, outperforming the state-of-the-art approaches (training from scratch) by more than 10.21%. Additionally, we reveal that SiRi performs surprisingly superior even with limited training data. We also extend it to transformer-based visual grounding models and other vision-language tasks to verify the validity.
PDF Abstract

