Source Identification in Abstractive Summarization
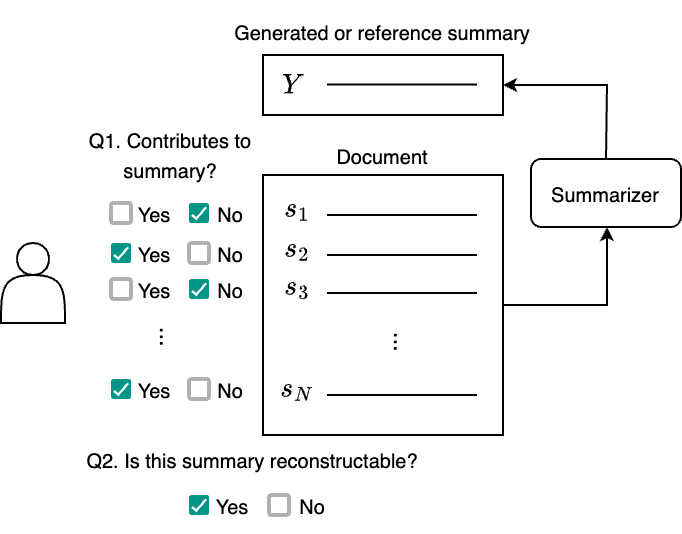
Neural abstractive summarization models make summaries in an end-to-end manner, and little is known about how the source information is actually converted into summaries. In this paper, we define input sentences that contain essential information in the generated summary as $\textit{source sentences}$ and study how abstractive summaries are made by analyzing the source sentences. To this end, we annotate source sentences for reference summaries and system summaries generated by PEGASUS on document-summary pairs sampled from the CNN/DailyMail and XSum datasets. We also formulate automatic source sentence detection and compare multiple methods to establish a strong baseline for the task. Experimental results show that the perplexity-based method performs well in highly abstractive settings, while similarity-based methods perform robustly in relatively extractive settings. Our code and data are available at https://github.com/suhara/sourcesum.
PDF Abstract


