Stella Nera: Achieving 161 TOp/s/W with Multiplier-free DNN Acceleration based on Approximate Matrix Multiplication
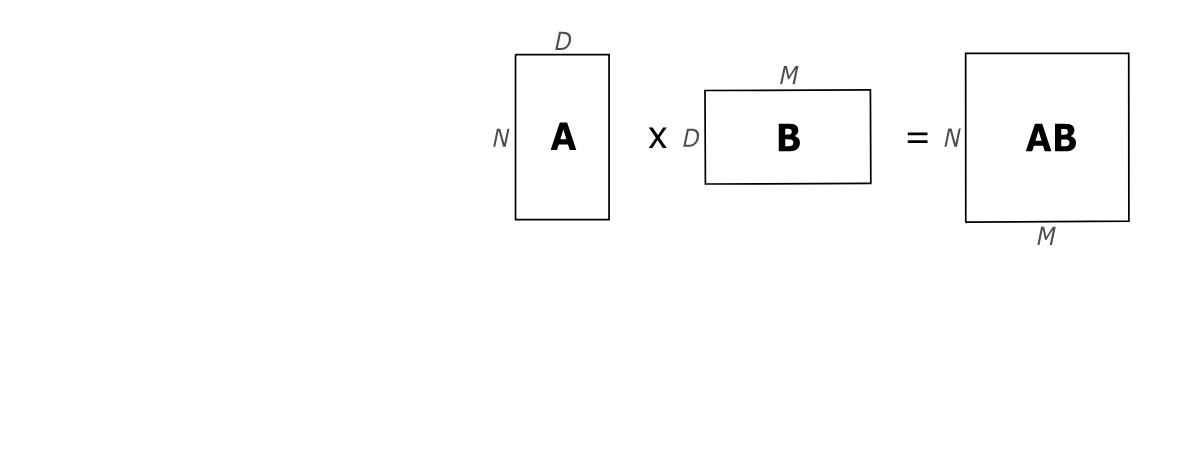
From classical HPC to deep learning, MatMul is at the heart of today's computing. The recent Maddness method approximates MatMul without the need for multiplication by using a hash-based version of product quantization (PQ) indexing into a look-up table (LUT). Stella Nera is the first Maddness accelerator and it achieves 15x higher area efficiency (GMAC/s/mm^2) and more than 25x higher energy efficiency (TMAC/s/W) than direct MatMul accelerators implemented in the same technology. The hash function is a decision tree, which allows for an efficient hardware implementation as the multiply-accumulate operations are replaced by decision tree passes and LUT lookups. The entire Maddness MatMul can be broken down into parts that allow an effective implementation with small computing units and memories, allowing it to reach extreme efficiency while remaining generically applicable for MatMul tasks. In a commercial 14nm technology and scaled to 3nm, we achieve an energy efficiency of 161 TOp/s/W@0.55V with a Top-1 accuracy on CIFAR-10 of more than 92.5% using ResNet9.
PDF Abstract

