StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators
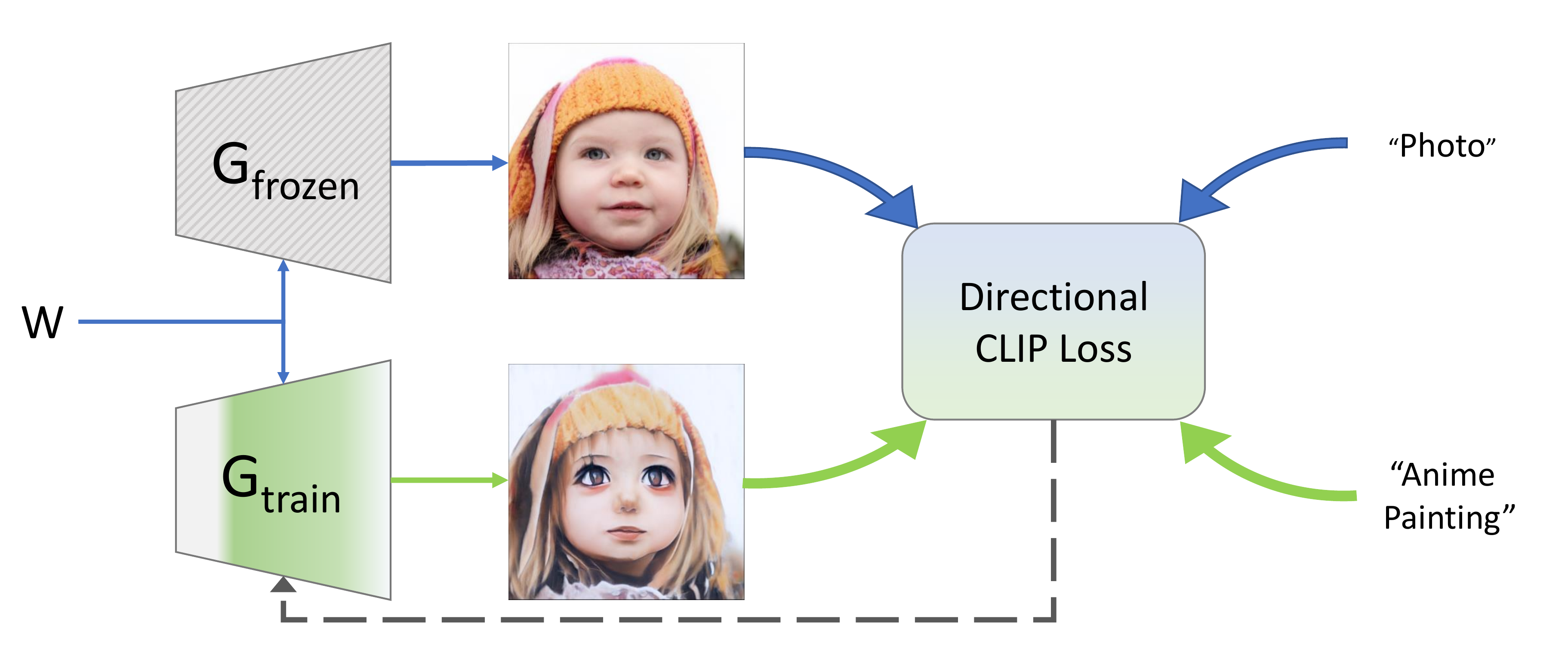
Can a generative model be trained to produce images from a specific domain, guided by a text prompt only, without seeing any image? In other words: can an image generator be trained "blindly"? Leveraging the semantic power of large scale Contrastive-Language-Image-Pre-training (CLIP) models, we present a text-driven method that allows shifting a generative model to new domains, without having to collect even a single image. We show that through natural language prompts and a few minutes of training, our method can adapt a generator across a multitude of domains characterized by diverse styles and shapes. Notably, many of these modifications would be difficult or outright impossible to reach with existing methods. We conduct an extensive set of experiments and comparisons across a wide range of domains. These demonstrate the effectiveness of our approach and show that our shifted models maintain the latent-space properties that make generative models appealing for downstream tasks.
PDF Abstract Colab
Colab
 Spaces
Spaces



 FFHQ
FFHQ
 LSUN
LSUN
 AFHQ
AFHQ
