Successive Halving Top-k Operator
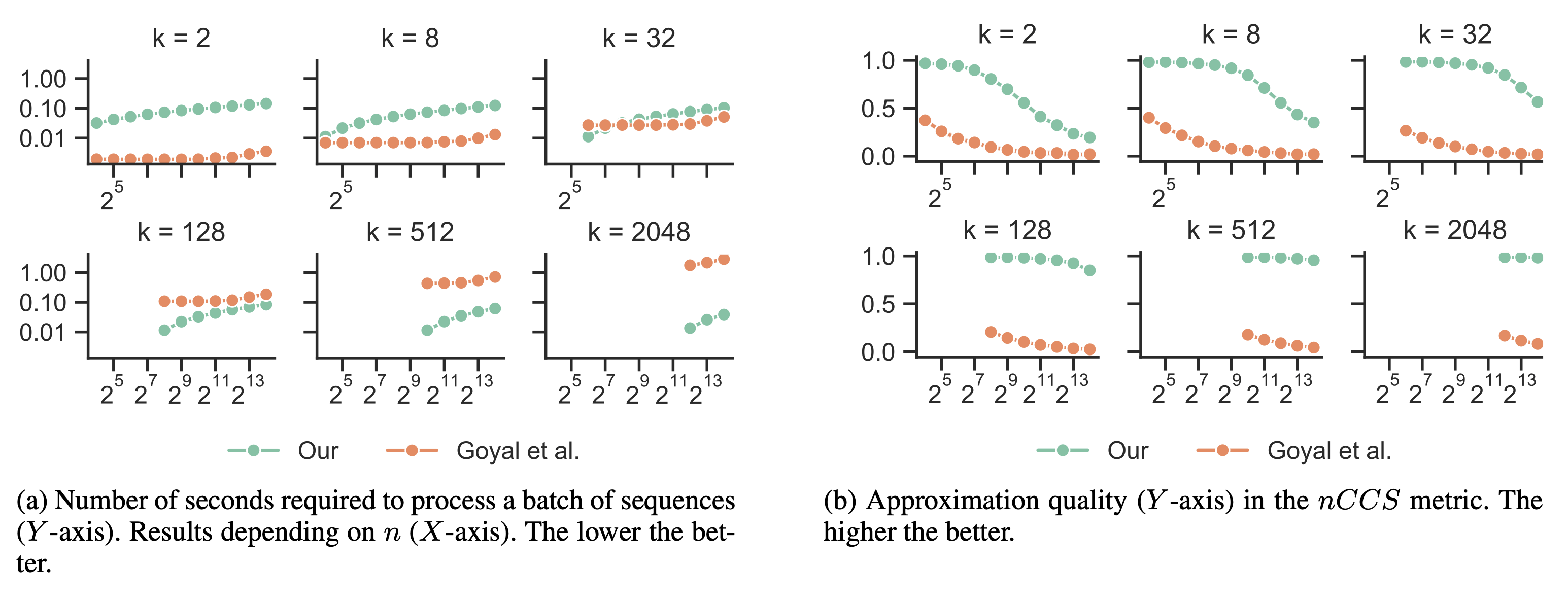
We propose a differentiable successive halving method of relaxing the top-k operator, rendering gradient-based optimization possible. The need to perform softmax iteratively on the entire vector of scores is avoided by using a tournament-style selection. As a result, a much better approximation of top-k with lower computational cost is achieved compared to the previous approach.
PDF Abstract
Tasks
Datasets
Add Datasets
introduced or used in this paper
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
