Synchformer: Efficient Synchronization from Sparse Cues
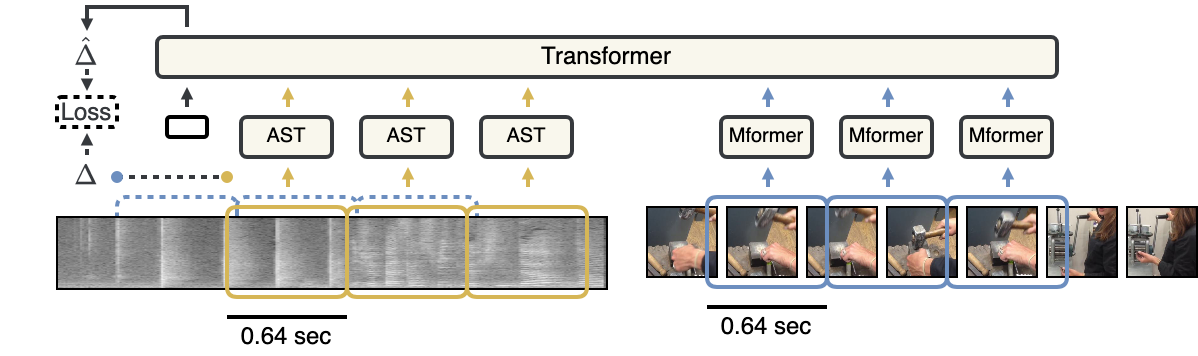
Our objective is audio-visual synchronization with a focus on 'in-the-wild' videos, such as those on YouTube, where synchronization cues can be sparse. Our contributions include a novel audio-visual synchronization model, and training that decouples feature extraction from synchronization modelling through multi-modal segment-level contrastive pre-training. This approach achieves state-of-the-art performance in both dense and sparse settings. We also extend synchronization model training to AudioSet a million-scale 'in-the-wild' dataset, investigate evidence attribution techniques for interpretability, and explore a new capability for synchronization models: audio-visual synchronizability.
PDF AbstractCode
 Colab
Colab


Datasets
 VGG-Sound
VGG-Sound
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
