Temporally Grounding Language Queries in Videos by Contextual Boundary-aware Prediction
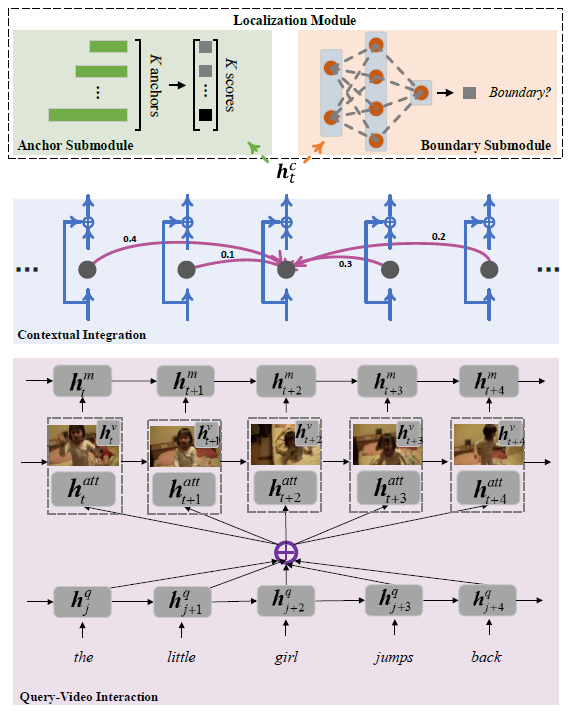
The task of temporally grounding language queries in videos is to temporally localize the best matched video segment corresponding to a given language (sentence). It requires certain models to simultaneously perform visual and linguistic understandings. Previous work predominantly ignores the precision of segment localization. Sliding window based methods use predefined search window sizes, which suffer from redundant computation, while existing anchor-based approaches fail to yield precise localization. We address this issue by proposing an end-to-end boundary-aware model, which uses a lightweight branch to predict semantic boundaries corresponding to the given linguistic information. To better detect semantic boundaries, we propose to aggregate contextual information by explicitly modeling the relationship between the current element and its neighbors. The most confident segments are subsequently selected based on both anchor and boundary predictions at the testing stage. The proposed model, dubbed Contextual Boundary-aware Prediction (CBP), outperforms its competitors with a clear margin on three public datasets. All codes are available on https://github.com/JaywongWang/CBP .
PDF Abstract

 ActivityNet
ActivityNet
 Charades
Charades
 ActivityNet Captions
ActivityNet Captions
 Charades-STA
Charades-STA
