Self-Supervised Aggregation of Diverse Experts for Test-Agnostic Long-Tailed Recognition
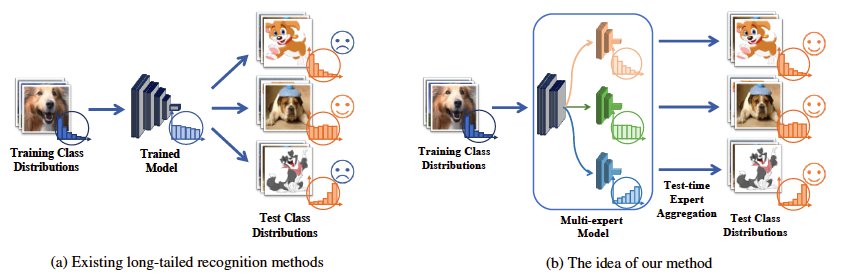
Existing long-tailed recognition methods, aiming to train class-balanced models from long-tailed data, generally assume the models would be evaluated on the uniform test class distribution. However, practical test class distributions often violate this assumption (e.g., being either long-tailed or even inversely long-tailed), which may lead existing methods to fail in real applications. In this paper, we study a more practical yet challenging task, called test-agnostic long-tailed recognition, where the training class distribution is long-tailed while the test class distribution is agnostic and not necessarily uniform. In addition to the issue of class imbalance, this task poses another challenge: the class distribution shift between the training and test data is unknown. To tackle this task, we propose a novel approach, called Self-supervised Aggregation of Diverse Experts, which consists of two strategies: (i) a new skill-diverse expert learning strategy that trains multiple experts from a single and stationary long-tailed dataset to separately handle different class distributions; (ii) a novel test-time expert aggregation strategy that leverages self-supervision to aggregate the learned multiple experts for handling unknown test class distributions. We theoretically show that our self-supervised strategy has a provable ability to simulate test-agnostic class distributions. Promising empirical results demonstrate the effectiveness of our method on both vanilla and test-agnostic long-tailed recognition. Code is available at \url{https://github.com/Vanint/SADE-AgnosticLT}.
PDF Abstract


 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
 iNaturalist
iNaturalist

