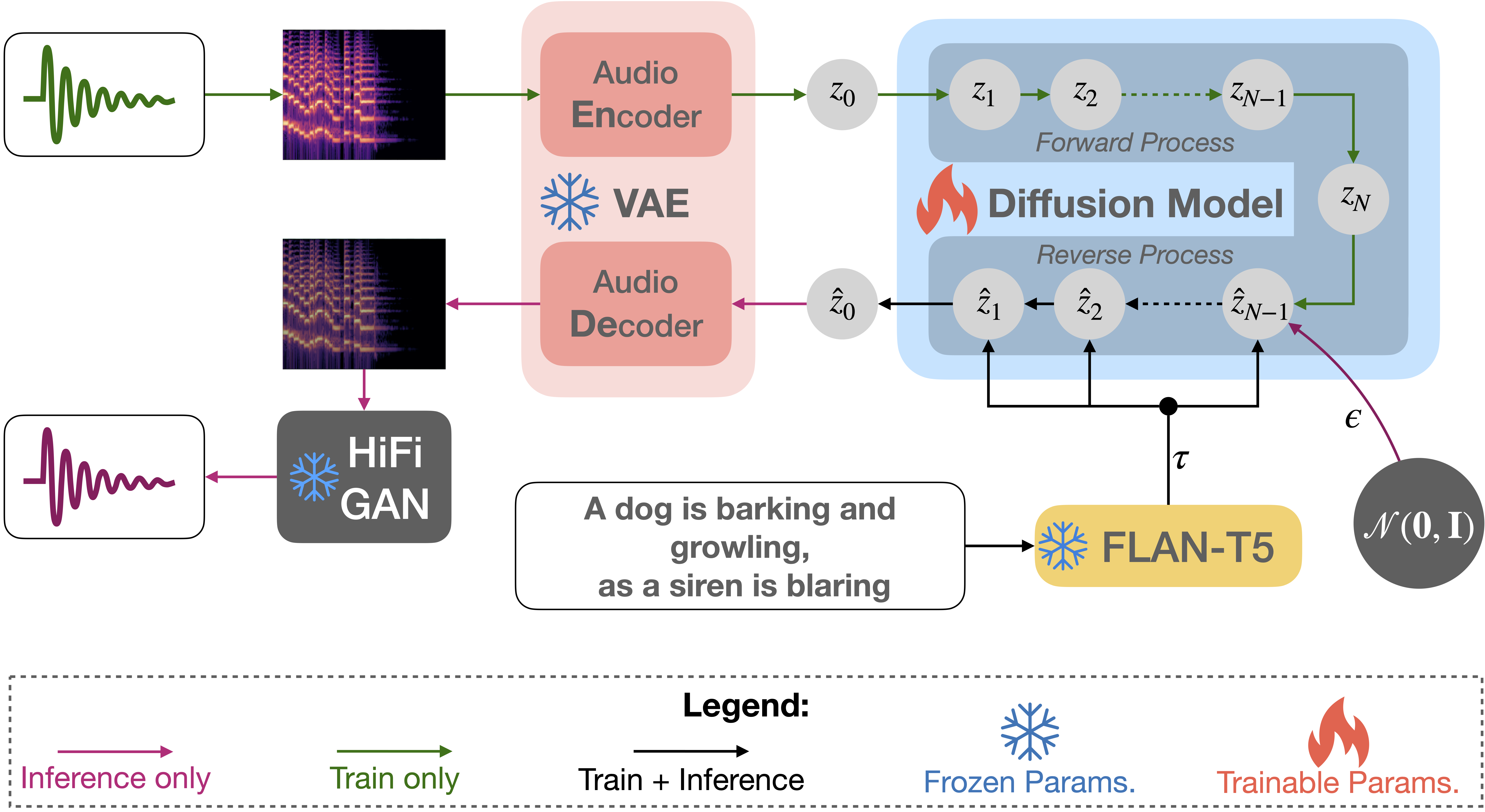
Text-to-Audio Generation using Instruction-Tuned LLM and Latent Diffusion Model
The immense scale of the recent large language models (LLM) allows many interesting properties, such as, instruction- and chain-of-thought-based fine-tuning, that has significantly improved zero- and few-shot performance in many natural language processing (NLP) tasks. Inspired by such successes, we adopt such an instruction-tuned LLM Flan-T5 as the text encoder for text-to-audio (TTA) generation -- a task where the goal is to generate an audio from its textual description. The prior works on TTA either pre-trained a joint text-audio encoder or used a non-instruction-tuned model, such as, T5. Consequently, our latent diffusion model (LDM)-based approach TANGO outperforms the state-of-the-art AudioLDM on most metrics and stays comparable on the rest on AudioCaps test set, despite training the LDM on a 63 times smaller dataset and keeping the text encoder frozen. This improvement might also be attributed to the adoption of audio pressure level-based sound mixing for training set augmentation, whereas the prior methods take a random mix.
PDF Abstract Colab
Colab
 Spaces
Spaces



 AudioSet
AudioSet
 ESC-50
ESC-50
 AudioCaps
AudioCaps

