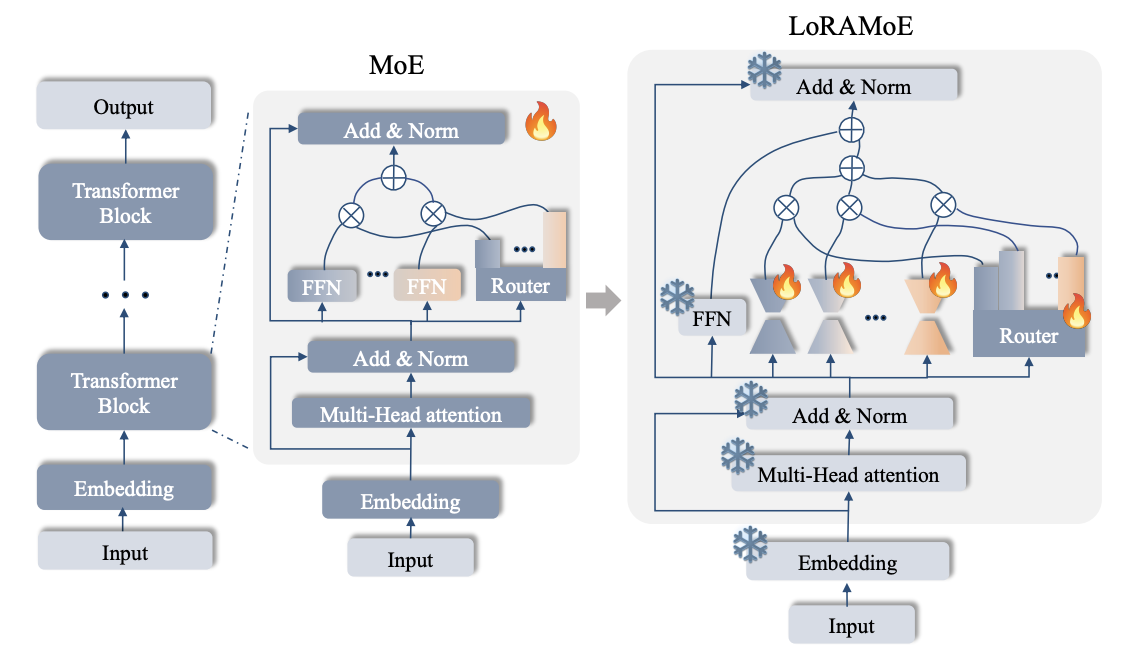
LoRAMoE: Alleviate World Knowledge Forgetting in Large Language Models via MoE-Style Plugin
Supervised fine-tuning (SFT) is a crucial step for large language models (LLMs), enabling them to align with human instructions and enhance their capabilities in downstream tasks. Increasing instruction data substantially is a direct solution to align the model with a broader range of downstream tasks or notably improve its performance on a specific task. However, we find that large-scale increases in instruction data can damage the world knowledge previously stored in LLMs. To address this challenge, we propose LoRAMoE, a novelty framework that introduces several low-rank adapters (LoRA) and integrates them by using a router network, like a plugin version of Mixture of Experts (MoE). It freezes the backbone model and forces a portion of LoRAs to focus on leveraging world knowledge to solve downstream tasks, to alleviate world knowledge-edge forgetting. Experimental results show that, as the instruction data increases, LoRAMoE can significantly improve the ability to process downstream tasks, while maintaining the world knowledge stored in the LLM.
PDF Abstract



 Natural Questions
Natural Questions
 WSC
WSC
 MultiRC
MultiRC
 ReCoRD
ReCoRD
 FLoRes
FLoRes
