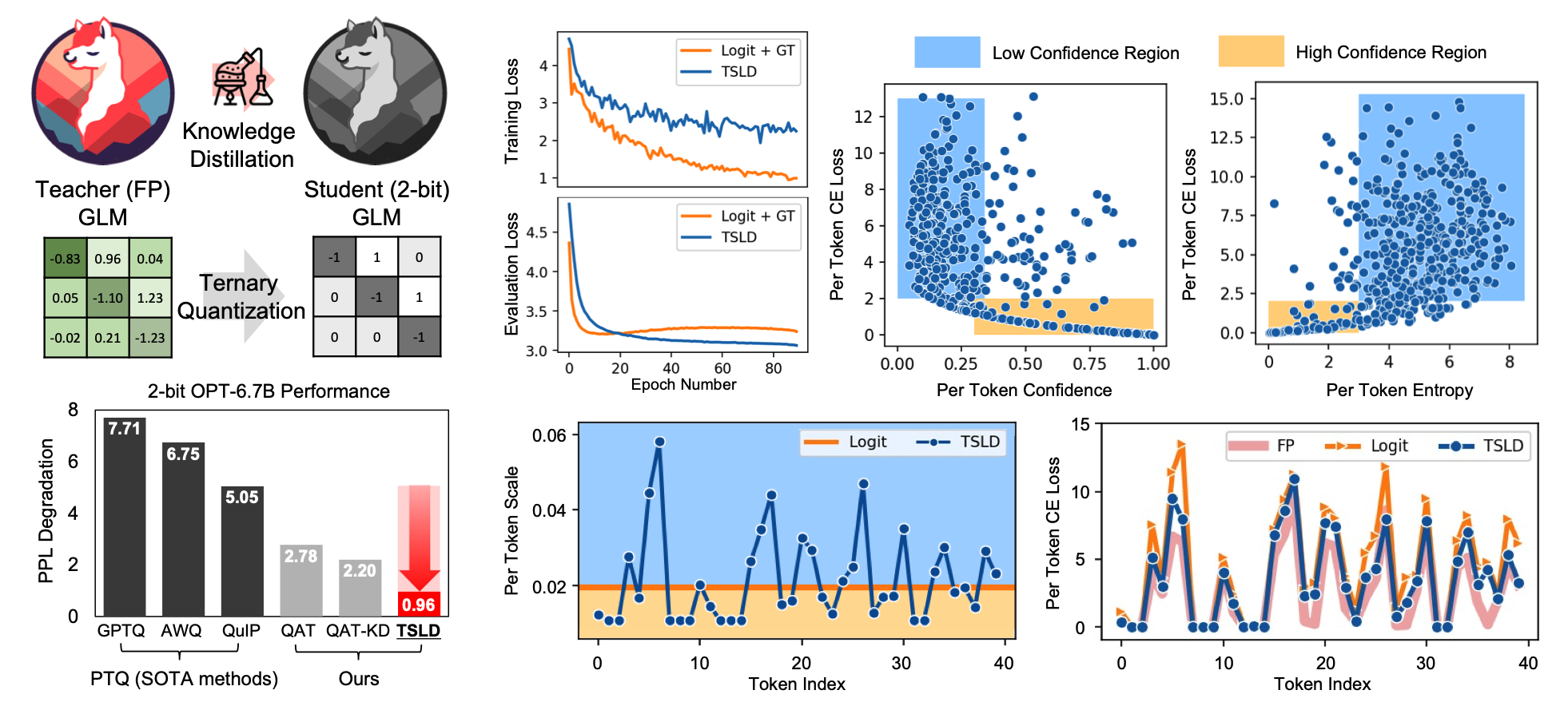
Token-Scaled Logit Distillation for Ternary Weight Generative Language Models
Generative Language Models (GLMs) have shown impressive performance in tasks such as text generation, understanding, and reasoning. However, the large model size poses challenges for practical deployment. To solve this problem, Quantization-Aware Training (QAT) has become increasingly popular. However, current QAT methods for generative models have resulted in a noticeable loss of accuracy. To counteract this issue, we propose a novel knowledge distillation method specifically designed for GLMs. Our method, called token-scaled logit distillation, prevents overfitting and provides superior learning from the teacher model and ground truth. This research marks the first evaluation of ternary weight quantization-aware training of large-scale GLMs with less than 1.0 degradation in perplexity and achieves enhanced accuracy in tasks like common-sense QA and arithmetic reasoning as well as natural language understanding. Our code is available at https://github.com/aiha-lab/TSLD.
PDF Abstract NeurIPS 2023 PDF NeurIPS 2023 Abstract


 GLUE
GLUE
 GSM8K
GSM8K
 CoLA
CoLA
 PIQA
PIQA
 OpenBookQA
OpenBookQA
