Towards 3D Human Pose Estimation in the Wild: a Weakly-supervised Approach
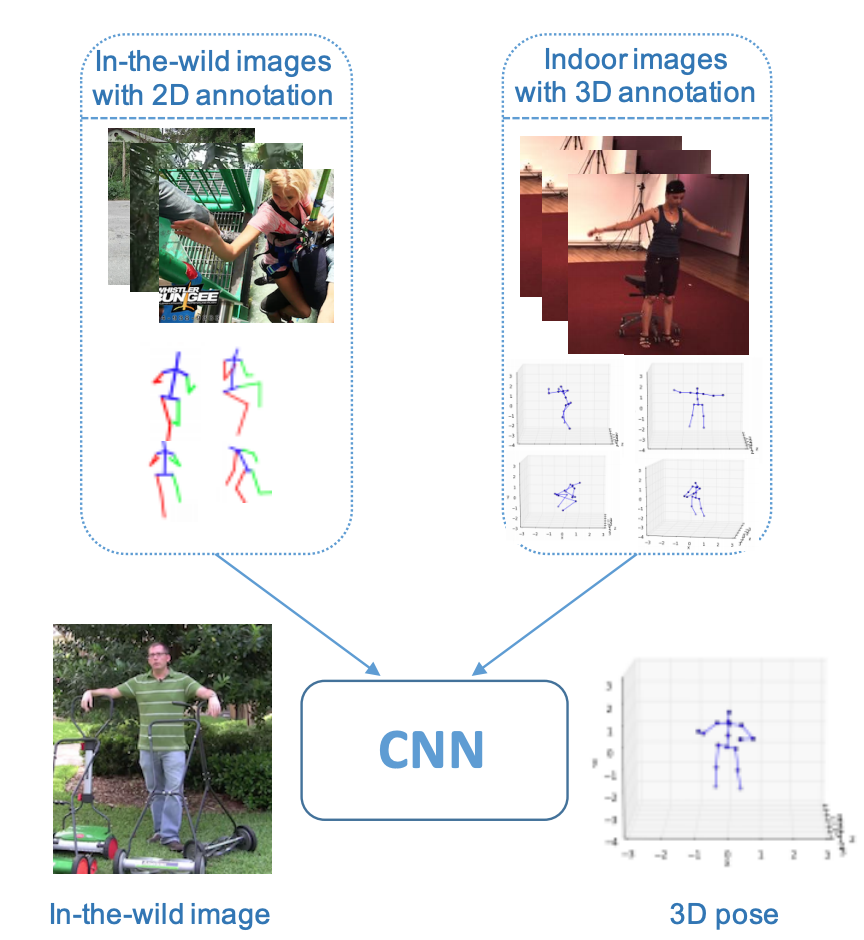
In this paper, we study the task of 3D human pose estimation in the wild. This task is challenging due to lack of training data, as existing datasets are either in the wild images with 2D pose or in the lab images with 3D pose. We propose a weakly-supervised transfer learning method that uses mixed 2D and 3D labels in a unified deep neutral network that presents two-stage cascaded structure. Our network augments a state-of-the-art 2D pose estimation sub-network with a 3D depth regression sub-network. Unlike previous two stage approaches that train the two sub-networks sequentially and separately, our training is end-to-end and fully exploits the correlation between the 2D pose and depth estimation sub-tasks. The deep features are better learnt through shared representations. In doing so, the 3D pose labels in controlled lab environments are transferred to in the wild images. In addition, we introduce a 3D geometric constraint to regularize the 3D pose prediction, which is effective in the absence of ground truth depth labels. Our method achieves competitive results on both 2D and 3D benchmarks.
PDF Abstract ICCV 2017 PDF ICCV 2017 AbstractCode







 Human3.6M
Human3.6M
 MPII
MPII
 GPA
GPA
Results from the Paper

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| 3D Human Pose Estimation | Geometric Pose Affordance | Baseline model | MPJPE (CS) | 99.4 | # 1 | |
| MPJPE (CA) | 89.2 | # 1 | ||||
| PCK3D (CS) | 81.3 | # 1 | ||||
| PCK3D (CA) | 83.6 | # 1 | ||||
| Monocular 3D Human Pose Estimation | Human3.6M | Weakly Supervised Transfer Learning | Average MPJPE (mm) | 64.9 | # 32 | |
| Use Video Sequence | No | # 1 | ||||
| Frames Needed | 1 | # 1 | ||||
| Need Ground Truth 2D Pose | No | # 1 |
