Towards Efficient SDRTV-to-HDRTV by Learning from Image Formation
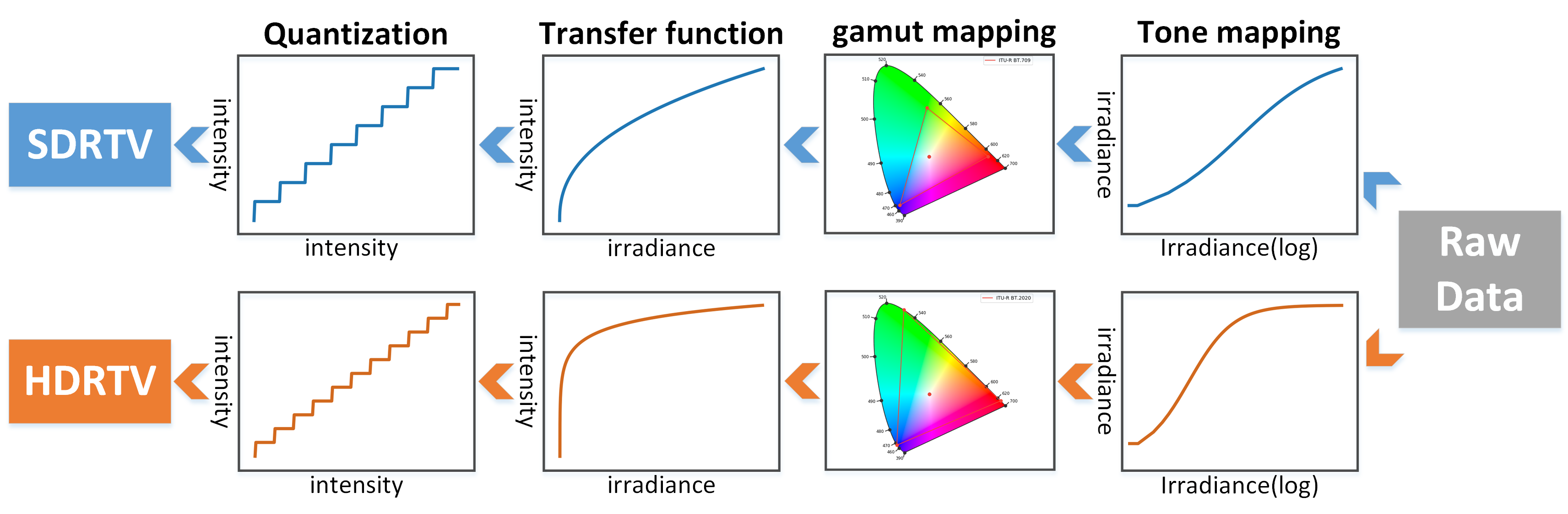
Modern displays are capable of rendering video content with high dynamic range (HDR) and wide color gamut (WCG). However, the majority of available resources are still in standard dynamic range (SDR). As a result, there is significant value in transforming existing SDR content into the HDRTV standard. In this paper, we define and analyze the SDRTV-to-HDRTV task by modeling the formation of SDRTV/HDRTV content. Our analysis and observations indicate that a naive end-to-end supervised training pipeline suffers from severe gamut transition errors. To address this issue, we propose a novel three-step solution pipeline called HDRTVNet++, which includes adaptive global color mapping, local enhancement, and highlight refinement. The adaptive global color mapping step uses global statistics as guidance to perform image-adaptive color mapping. A local enhancement network is then deployed to enhance local details. Finally, we combine the two sub-networks above as a generator and achieve highlight consistency through GAN-based joint training. Our method is primarily designed for ultra-high-definition TV content and is therefore effective and lightweight for processing 4K resolution images. We also construct a dataset using HDR videos in the HDR10 standard, named HDRTV1K that contains 1235 and 117 training images and 117 testing images, all in 4K resolution. Besides, we select five metrics to evaluate the results of SDRTV-to-HDRTV algorithms. Our final results demonstrate state-of-the-art performance both quantitatively and visually. The code, model and dataset are available at https://github.com/xiaom233/HDRTVNet-plus.
PDF Abstract

