Towards Explainable 3D Grounded Visual Question Answering: A New Benchmark and Strong Baseline
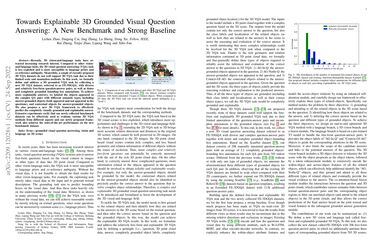
Recently, 3D vision-and-language tasks have attracted increasing research interest. Compared to other vision-and-language tasks, the 3D visual question answering (VQA) task is less exploited and is more susceptible to language priors and co-reference ambiguity. Meanwhile, a couple of recently proposed 3D VQA datasets do not well support 3D VQA task due to their limited scale and annotation methods. In this work, we formally define and address a 3D grounded VQA task by collecting a new 3D VQA dataset, referred to as FE-3DGQA, with diverse and relatively free-form question-answer pairs, as well as dense and completely grounded bounding box annotations. To achieve more explainable answers, we labelled the objects appeared in the complex QA pairs with different semantic types, including answer-grounded objects (both appeared and not appeared in the questions), and contextual objects for answer-grounded objects. We also propose a new 3D VQA framework to effectively predict the completely visually grounded and explainable answer. Extensive experiments verify that our newly collected benchmark datasets can be effectively used to evaluate various 3D VQA methods from different aspects and our newly proposed framework also achieves state-of-the-art performance on the new benchmark dataset. Both the newly collected dataset and our codes will be publicly available at http://github.com/zlccccc/3DGQA.
PDF Abstract



 Visual Question Answering
Visual Question Answering
 ScanNet
ScanNet
 3RScan
3RScan
