Training Simplification and Model Simplification for Deep Learning: A Minimal Effort Back Propagation Method
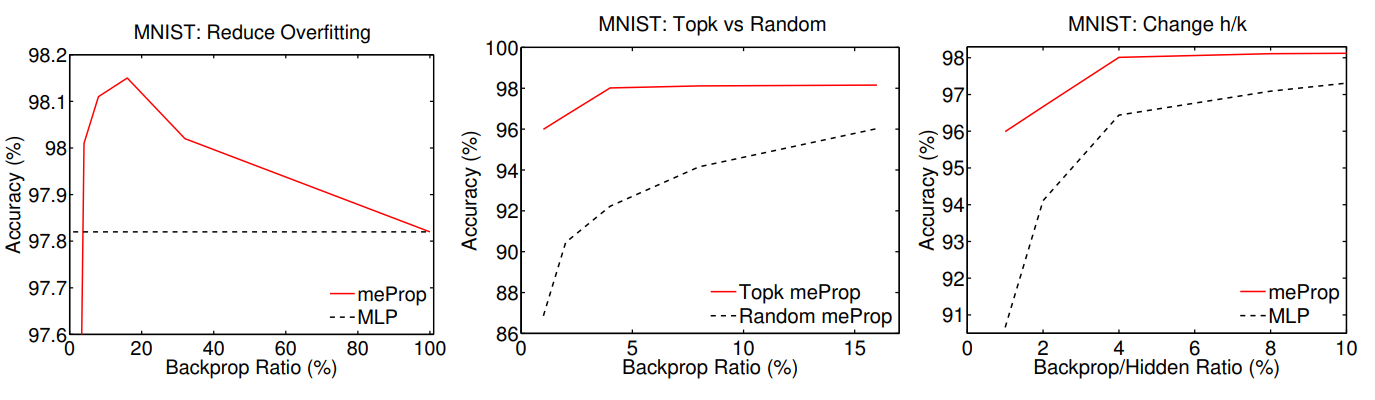
We propose a simple yet effective technique to simplify the training and the resulting model of neural networks. In back propagation, only a small subset of the full gradient is computed to update the model parameters. The gradient vectors are sparsified in such a way that only the top-k elements (in terms of magnitude) are kept. As a result, only k rows or columns (depending on the layout) of the weight matrix are modified, leading to a linear reduction in the computational cost. Based on the sparsified gradients, we further simplify the model by eliminating the rows or columns that are seldom updated, which will reduce the computational cost both in the training and decoding, and potentially accelerate decoding in real-world applications. Surprisingly, experimental results demonstrate that most of time we only need to update fewer than 5% of the weights at each back propagation pass. More interestingly, the accuracy of the resulting models is actually improved rather than degraded, and a detailed analysis is given. The model simplification results show that we could adaptively simplify the model which could often be reduced by around 9x, without any loss on accuracy or even with improved accuracy. The codes, including the extension, are available at https://github.com/lancopku/meSimp
PDF Abstract
 MNIST
MNIST
