Transcending Adversarial Perturbations: Manifold-Aided Adversarial Examples with Legitimate Semantics
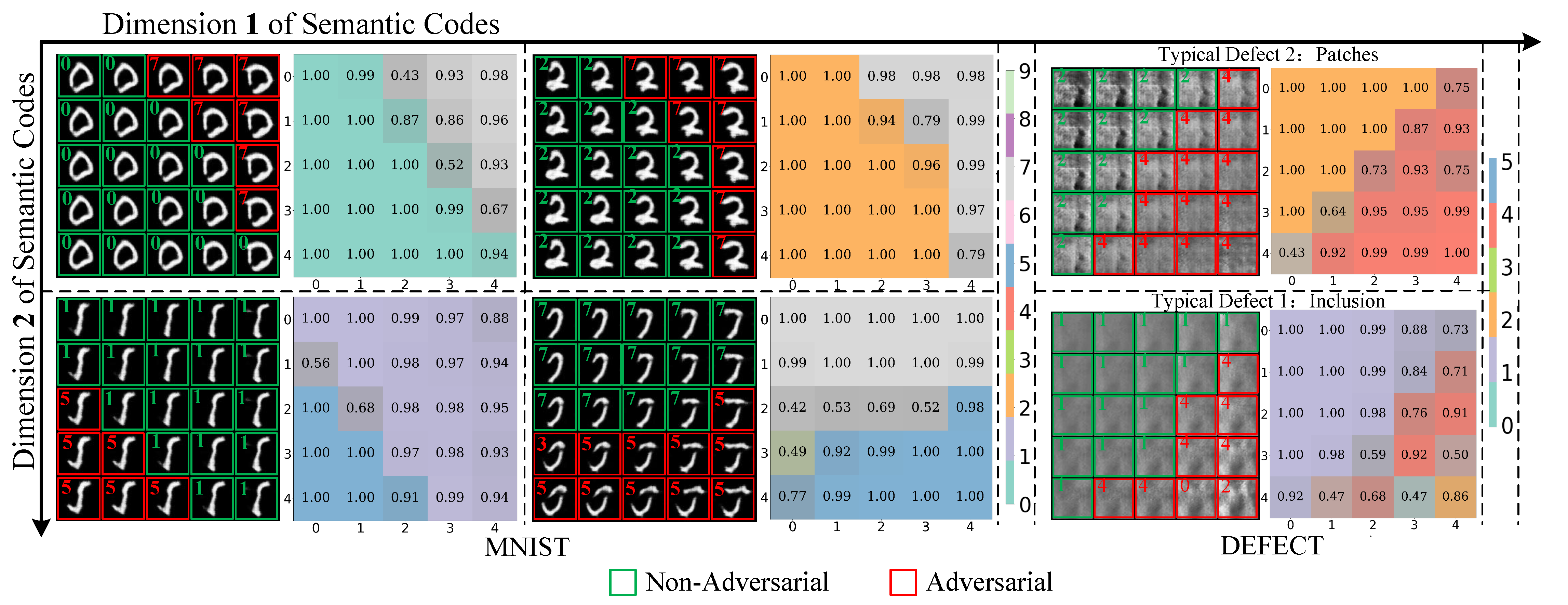
Deep neural networks were significantly vulnerable to adversarial examples manipulated by malicious tiny perturbations. Although most conventional adversarial attacks ensured the visual imperceptibility between adversarial examples and corresponding raw images by minimizing their geometric distance, these constraints on geometric distance led to limited attack transferability, inferior visual quality, and human-imperceptible interpretability. In this paper, we proposed a supervised semantic-transformation generative model to generate adversarial examples with real and legitimate semantics, wherein an unrestricted adversarial manifold containing continuous semantic variations was constructed for the first time to realize a legitimate transition from non-adversarial examples to adversarial ones. Comprehensive experiments on MNIST and industrial defect datasets showed that our adversarial examples not only exhibited better visual quality but also achieved superior attack transferability and more effective explanations for model vulnerabilities, indicating their great potential as generic adversarial examples. The code and pre-trained models were available at https://github.com/shuaili1027/MAELS.git.
PDF Abstract
