Transformer Quality in Linear Time
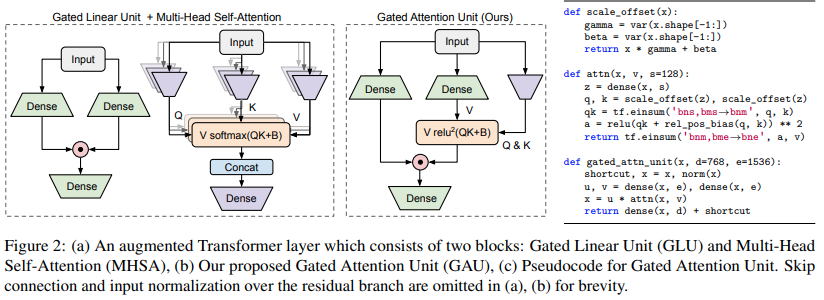
We revisit the design choices in Transformers, and propose methods to address their weaknesses in handling long sequences. First, we propose a simple layer named gated attention unit, which allows the use of a weaker single-head attention with minimal quality loss. We then propose a linear approximation method complementary to this new layer, which is accelerator-friendly and highly competitive in quality. The resulting model, named FLASH, matches the perplexity of improved Transformers over both short (512) and long (8K) context lengths, achieving training speedups of up to 4.9$\times$ on Wiki-40B and 12.1$\times$ on PG-19 for auto-regressive language modeling, and 4.8$\times$ on C4 for masked language modeling.
PDF AbstractCode



 C4
C4
 TriviaQA
TriviaQA

Methods
No methods listed for this paper. Add
relevant methods here
