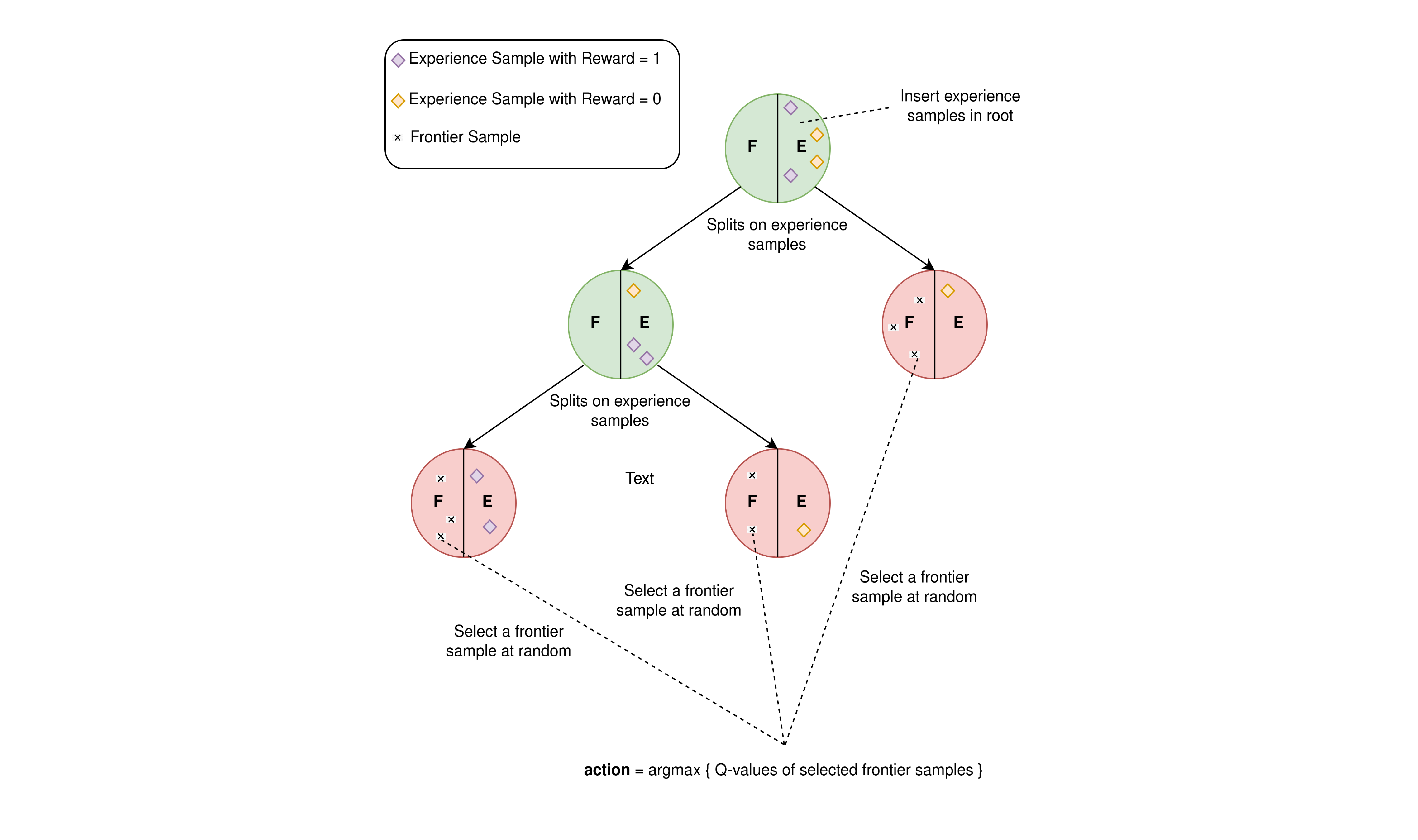
Tree-based Focused Web Crawling with Reinforcement Learning
A focused crawler aims at discovering as many web pages relevant to a target topic as possible, while avoiding irrelevant ones. Reinforcement Learning (RL) has been utilized to optimize focused crawling. In this paper, we propose TRES, an RL-empowered framework for focused crawling. We model the crawling environment as a Markov Decision Process, which the RL agent aims at solving by determining a good crawling strategy. Starting from a few human provided keywords and a small text corpus, that are expected to be relevant to the target topic, TRES follows a keyword set expansion procedure, which guides crawling, and trains a classifier that constitutes the reward function. To avoid a computationally infeasible brute force method for selecting a best action, we propose Tree-Frontier, a decision-tree-based algorithm that adaptively discretizes the large state and action spaces and finds only a few representative actions. Tree-Frontier allows the agent to be likely to select near-optimal actions by being greedy over selecting the best representative action. Experimentally, we show that TRES significantly outperforms state-of-the-art methods in terms of harvest rate (ratio of relevant pages crawled), while Tree-Frontier reduces by orders of magnitude the number of actions needed to be evaluated at each timestep.
PDF Abstract

