Troika: Multi-Path Cross-Modal Traction for Compositional Zero-Shot Learning
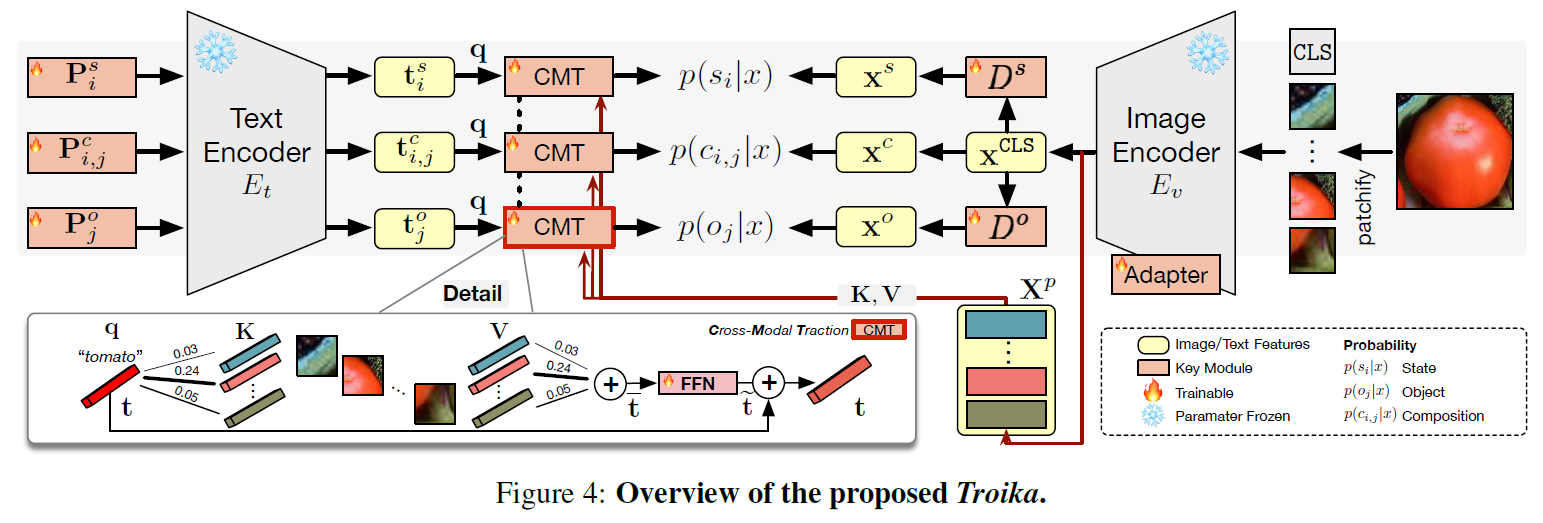
Recent compositional zero-shot learning (CZSL) methods adapt pre-trained vision-language models (VLMs) by constructing trainable prompts only for composed state-object pairs. Relying on learning the joint representation of seen compositions, these methods ignore the explicit modeling of the state and object, thus limiting the exploitation of pre-trained knowledge and generalization to unseen compositions. With a particular focus on the universality of the solution, in this work, we propose a novel paradigm for CZSL models that establishes three identification branches (i.e., Multi-Path) to jointly model the state, object, and composition. The presented Troika is our implementation that aligns the branch-specific prompt representations with decomposed visual features. To calibrate the bias between semantically similar multi-modal representations, we further devise a Cross-Modal Traction module into Troika that shifts the prompt representation towards the current visual content. We conduct extensive experiments on three popular benchmarks, where our method significantly outperforms existing methods in both closed-world and open-world settings. The code will be available at https://github.com/bighuang624/Troika.
PDF Abstract


 MIT-States
MIT-States
