TVR: A Large-Scale Dataset for Video-Subtitle Moment Retrieval
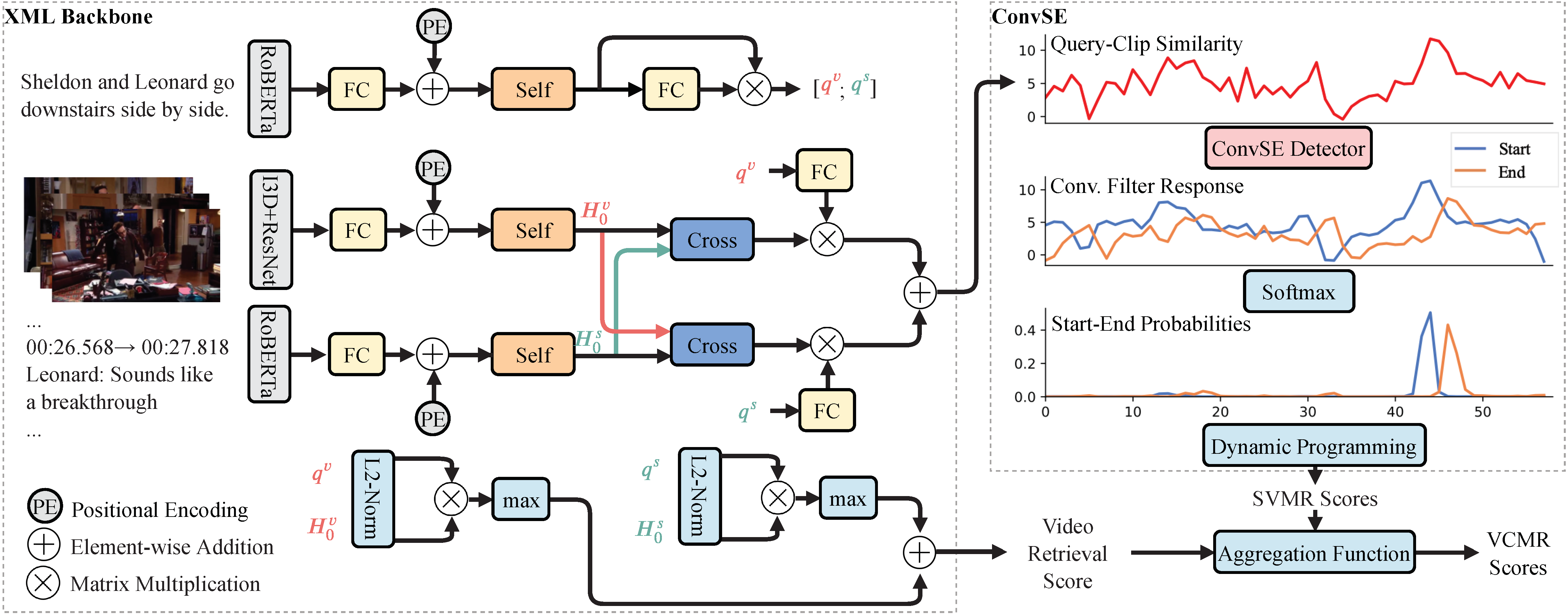
We introduce TV show Retrieval (TVR), a new multimodal retrieval dataset. TVR requires systems to understand both videos and their associated subtitle (dialogue) texts, making it more realistic. The dataset contains 109K queries collected on 21.8K videos from 6 TV shows of diverse genres, where each query is associated with a tight temporal window. The queries are also labeled with query types that indicate whether each of them is more related to video or subtitle or both, allowing for in-depth analysis of the dataset and the methods that built on top of it. Strict qualification and post-annotation verification tests are applied to ensure the quality of the collected data. Further, we present several baselines and a novel Cross-modal Moment Localization (XML ) network for multimodal moment retrieval tasks. The proposed XML model uses a late fusion design with a novel Convolutional Start-End detector (ConvSE), surpassing baselines by a large margin and with better efficiency, providing a strong starting point for future work. We have also collected additional descriptions for each annotated moment in TVR to form a new multimodal captioning dataset with 262K captions, named TV show Caption (TVC). Both datasets are publicly available. TVR: https://tvr.cs.unc.edu, TVC: https://tvr.cs.unc.edu/tvc.html.
PDF Abstract ECCV 2020 PDF ECCV 2020 Abstract


Datasets
Introduced in the Paper:
TVR TVC
TVC
Used in the Paper:
 Charades
Charades
 ActivityNet Captions
ActivityNet Captions
 Charades-STA
Charades-STA
 DiDeMo
DiDeMo
 TVQA
TVQA
 TVQA+
TVQA+

