Txt2Vid: Ultra-Low Bitrate Compression of Talking-Head Videos via Text
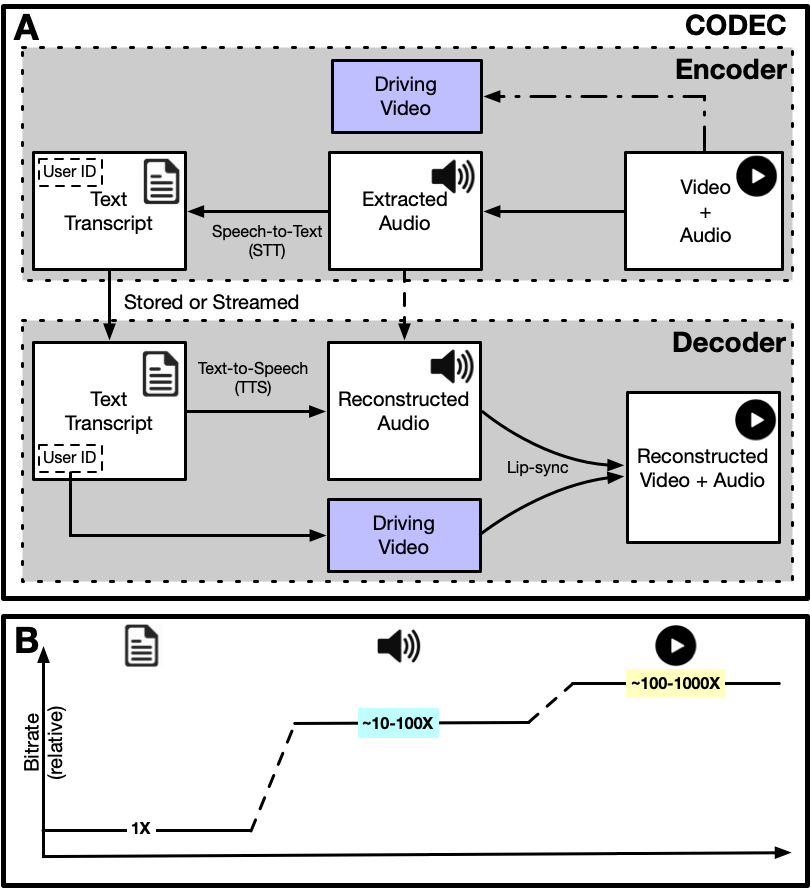
Video represents the majority of internet traffic today, driving a continual race between the generation of higher quality content, transmission of larger file sizes, and the development of network infrastructure. In addition, the recent COVID-19 pandemic fueled a surge in the use of video conferencing tools. Since videos take up considerable bandwidth (~100 Kbps to a few Mbps), improved video compression can have a substantial impact on network performance for live and pre-recorded content, providing broader access to multimedia content worldwide. We present a novel video compression pipeline, called Txt2Vid, which dramatically reduces data transmission rates by compressing webcam videos ("talking-head videos") to a text transcript. The text is transmitted and decoded into a realistic reconstruction of the original video using recent advances in deep learning based voice cloning and lip syncing models. Our generative pipeline achieves two to three orders of magnitude reduction in the bitrate as compared to the standard audio-video codecs (encoders-decoders), while maintaining equivalent Quality-of-Experience based on a subjective evaluation by users (n = 242) in an online study. The Txt2Vid framework opens up the potential for creating novel applications such as enabling audio-video communication during poor internet connectivity, or in remote terrains with limited bandwidth. The code for this work is available at https://github.com/tpulkit/txt2vid.git.
PDF Abstract




