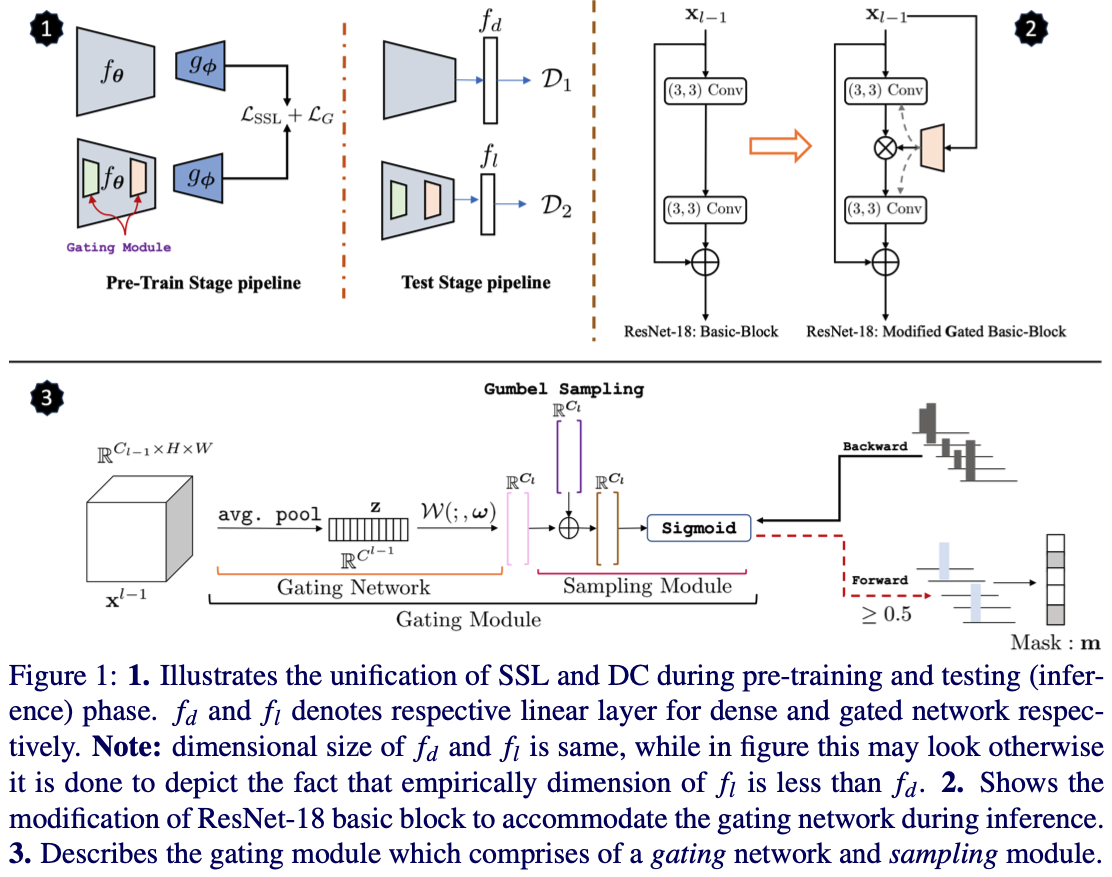
Unifying Synergies between Self-supervised Learning and Dynamic Computation
Computationally expensive training strategies make self-supervised learning (SSL) impractical for resource constrained industrial settings. Techniques like knowledge distillation (KD), dynamic computation (DC), and pruning are often used to obtain a lightweightmodel, which usually involves multiple epochs of fine-tuning (or distilling steps) of a large pre-trained model, making it more computationally challenging. In this work we present a novel perspective on the interplay between SSL and DC paradigms. In particular, we show that it is feasible to simultaneously learn a dense and gated sub-network from scratch in a SSL setting without any additional fine-tuning or pruning steps. The co-evolution during pre-training of both dense and gated encoder offers a good accuracy-efficiency trade-off and therefore yields a generic and multi-purpose architecture for application specific industrial settings. Extensive experiments on several image classification benchmarks including CIFAR-10/100, STL-10 and ImageNet-100, demonstrate that the proposed training strategy provides a dense and corresponding gated sub-network that achieves on-par performance compared with the vanilla self-supervised setting, but at a significant reduction in computation in terms of FLOPs, under a range of target budgets (td ).
PDF Abstract



 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
 STL-10
STL-10
