Universally Rank Consistent Ordinal Regression in Neural Networks
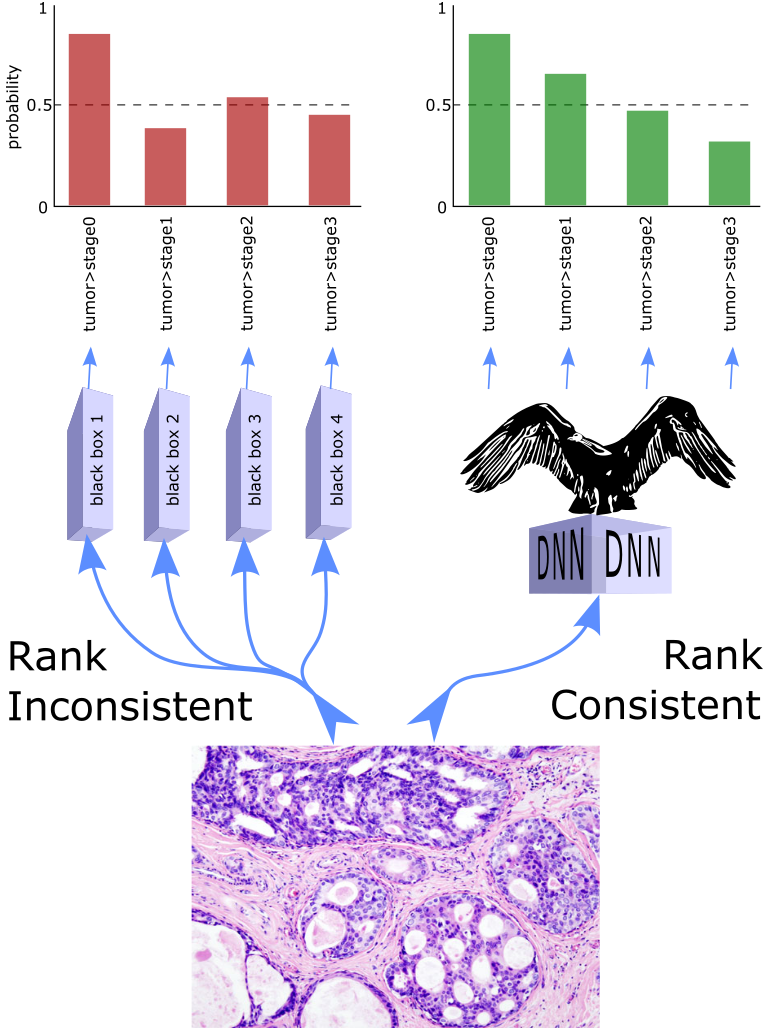
Despite the pervasiveness of ordinal labels in supervised learning, it remains common practice in deep learning to treat such problems as categorical classification using the categorical cross entropy loss. Recent methods attempting to address this issue while respecting the ordinal structure of the labels have resorted to converting ordinal regression into a series of extended binary classification subtasks. However, the adoption of such methods remains inconsistent due to theoretical and practical limitations. Here we address these limitations by demonstrating that the subtask probabilities form a Markov chain. We show how to straightforwardly modify neural network architectures to exploit this fact and thereby constrain predictions to be universally rank consistent. We furthermore prove that all rank consistent solutions can be represented within this formulation, and derive a loss function producing maximum likelihood parameter estimates. Using diverse benchmarks and the real-world application of a specialized recurrent neural network for COVID-19 prognosis, we demonstrate the practical superiority of this method versus the current state-of-the-art. The method is open sourced as user-friendly PyTorch and TensorFlow packages.
PDF Abstract


