Unsupervised Domain Adaptation of Black-Box Source Models
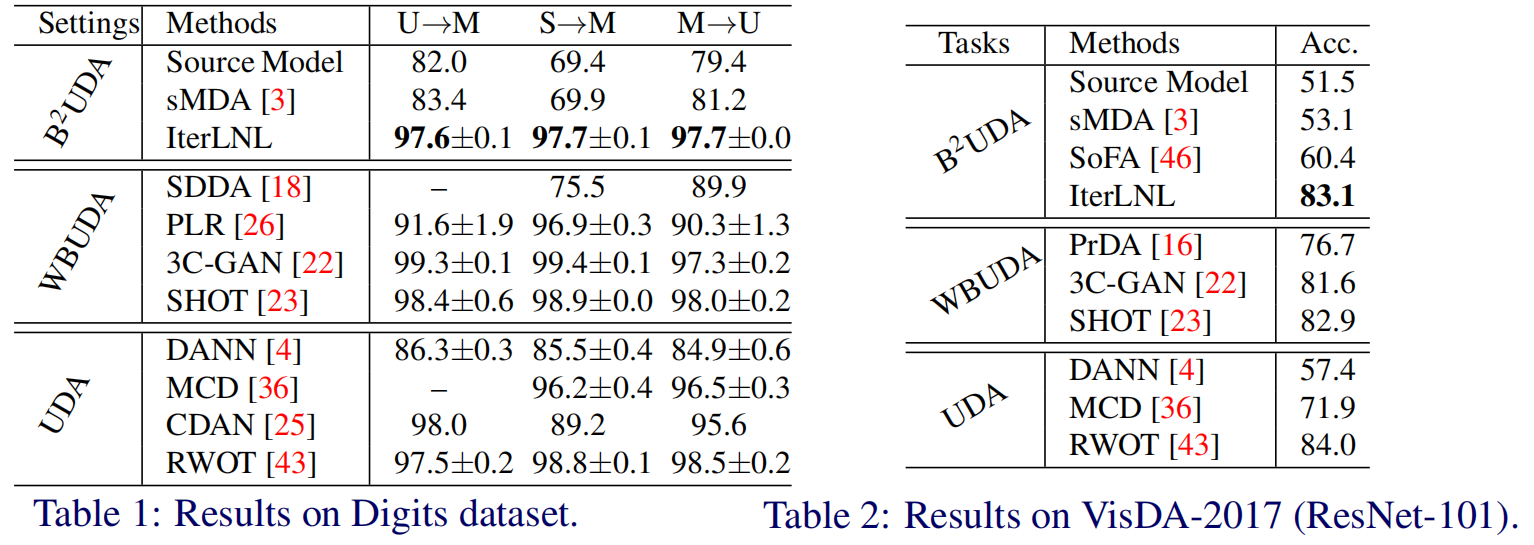
Unsupervised domain adaptation (UDA) aims to learn models for a target domain of unlabeled data by transferring knowledge from a labeled source domain. In the traditional UDA setting, labeled source data are assumed to be available for adaptation. Due to increasing concerns for data privacy, source-free UDA is highly appreciated as a new UDA setting, where only a trained source model is assumed to be available, while labeled source data remain private. However, trained source models may also be unavailable in practice since source models may have commercial values and exposing source models brings risks to the source domain, e.g., problems of model misuse and white-box attacks. In this work, we study a subtly different setting, named Black-Box Unsupervised Domain Adaptation (B$^2$UDA), where only the application programming interface of source model is accessible to the target domain; in other words, the source model itself is kept as a black-box one. To tackle B$^2$UDA, we propose a simple yet effective method, termed Iterative Learning with Noisy Labels (IterLNL). With black-box models as tools of noisy labeling, IterLNL conducts noisy labeling and learning with noisy labels (LNL), iteratively. To facilitate the implementation of LNL in B$^2$UDA, we estimate the noise rate from model predictions of unlabeled target data and propose category-wise sampling to tackle the unbalanced label noise among categories. Experiments on benchmark datasets show the efficacy of IterLNL. Given neither source data nor source models, IterLNL performs comparably with traditional UDA methods that make full use of labeled source data.
PDF Abstract


 MNIST
MNIST
 SVHN
SVHN
 Office-31
Office-31
 USPS
USPS
 VisDA-2017
VisDA-2017
